Architectural Insights: Designing Efficient Multi-Layered Caching With Instagram Example
DZone
FEBRUARY 27, 2024
Leveraging this hierarchical structure can significantly reduce latency and improve overall performance.
 Design Efficiency Example Latency
Design Efficiency Example Latency 
DZone
FEBRUARY 27, 2024
Leveraging this hierarchical structure can significantly reduce latency and improve overall performance.
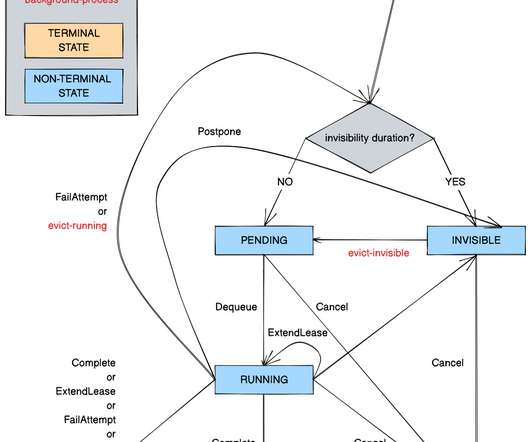
The Netflix TechBlog
SEPTEMBER 29, 2022
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. Over the past 2.5
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Scalegrid
JANUARY 25, 2024
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. These essential data points heavily influence both stability and efficiency within the system.

Dynatrace
SEPTEMBER 13, 2023
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.
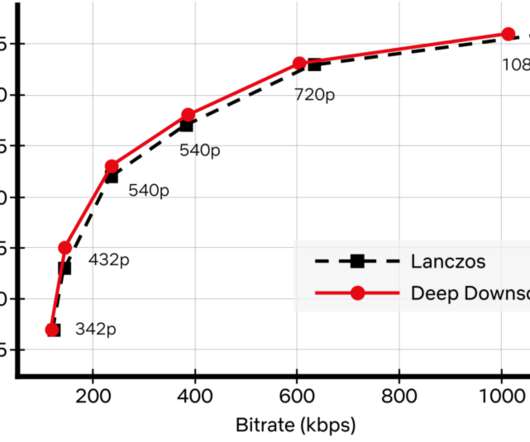
The Netflix TechBlog
NOVEMBER 17, 2022
For example, we invest in next-generation, royalty-free codecs and sophisticated video encoding optimizations. Video downscaling is the most pertinent example herein, which tailors our encoding to screen resolutions of different devices and optimizes picture quality under varying network conditions. A visual example is shown below.

Dynatrace
JANUARY 31, 2024
For example, a Stanford University and UC Berkeley team noted in a research study that ChatGPT behavior deteriorates over time. Using the example of a chatbot, once the user submits a natural language prompt, RAG summarizes that prompt using semantic data. Consequently, AI model drift and hallucinations emerge as primary concerns.
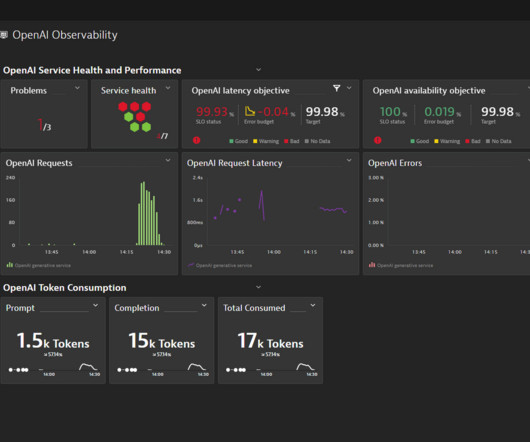
Dynatrace
JUNE 7, 2023
A typical design pattern is the use of a semantic search over a domain-specific knowledge base, like internal documentation, to provide the required context in the prompt. Our example dashboard below visualizes OpenAI token consumption. This includes OpenAI as well as Azure OpenAI services, such as GPT-3, Codex, DALL-E, or ChatGPT.

Expert insights. Personalized for you.



































Let's personalize your content