
Understanding and Managing Latency in APISIX: A Comprehensive Technical Guide
DZone
JANUARY 3, 2024
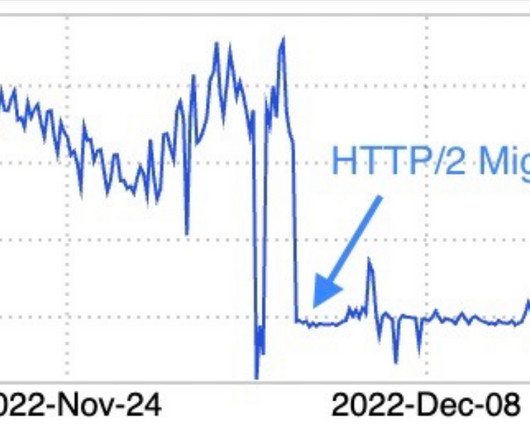
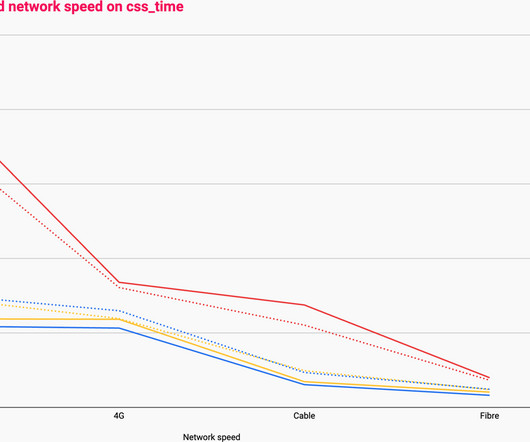
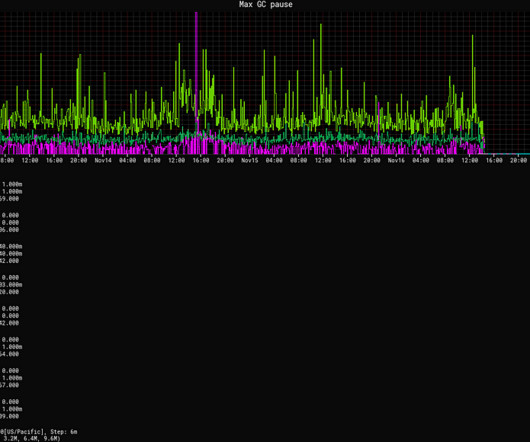
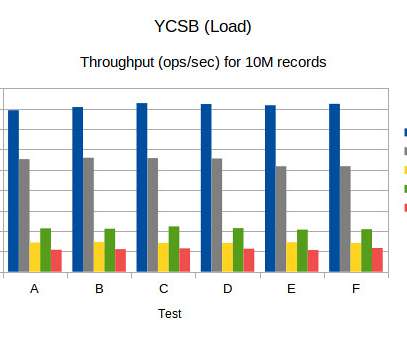
A common query from users revolves around the precise measurement of latency in APISIX. When utilizing APISIX, how should one address unusually high latency? In reality, discussions on latency measurement are centered around the performance and response time of API requests.








































Let's personalize your content