

Storage Types Used on Cloud Computing Platforms
DZone
JANUARY 24, 2024
Because of the emergence of cloud services, a broad range of storage choices are now easily available to fulfill the different demands of both organizations and people. These storage alternatives have been designed to meet a range of requirements, including performance, scalability, durability, and price.
























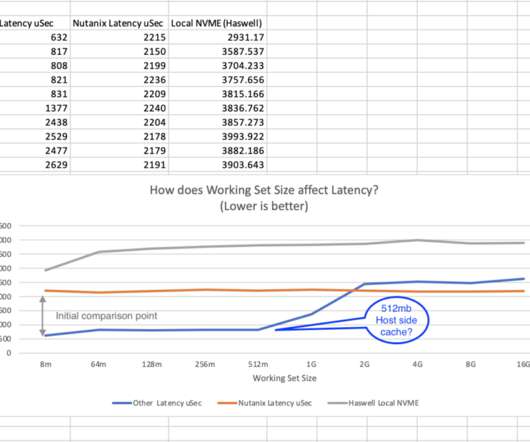
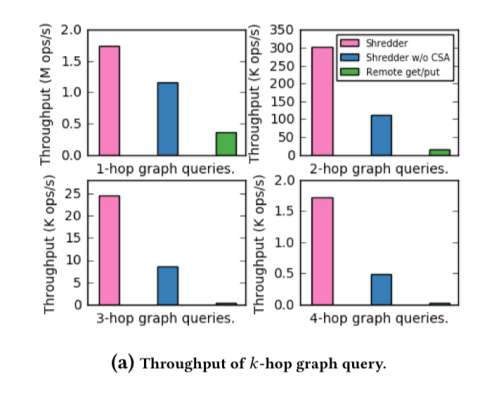





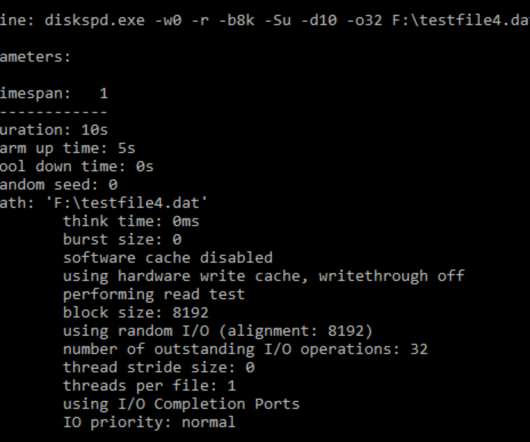












Let's personalize your content