This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Migrating Critical Traffic At Scale with No Downtime — Part 1 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Hundreds of millions of customers tune into Netflix every day, expecting an uninterrupted and immersive streaming experience. This approach has a handful of benefits.
Todays applications must simultaneously serve millions of users, so high performance is a hard requirement for this heavy load. When you consider marketing campaigns, seasonal spikes, or social media virality episodes, this demand can overshoot projections and bring systems to a grinding halt.
Migrating Critical Traffic At Scale with No Downtime — Part 2 Shyam Gala , Javier Fernandez-Ivern , Anup Rokkam Pratap , Devang Shah Picture yourself enthralled by the latest episode of your beloved Netflix series, delighting in an uninterrupted, high-definition streaming experience. This is where large-scale system migrations come into play.
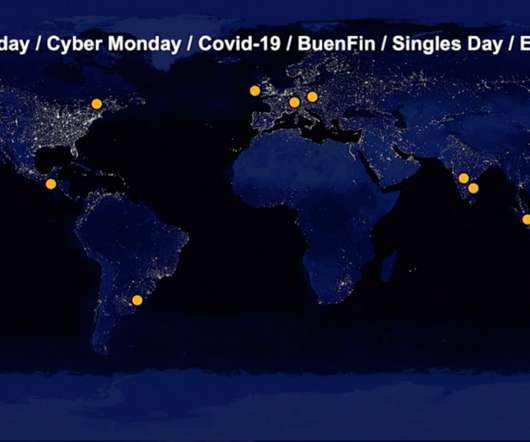
What’s the problem with Black Friday traffic? But that’s difficult when Black Friday traffic brings overwhelming and unpredictable peak loads to retailer websites and exposes the weakest points in a company’s infrastructure, threatening application performance and user experience. Why Black Friday traffic threatens customer experience.
How To Design For High-Traffic Events And Prevent Your Website From Crashing How To Design For High-Traffic Events And Prevent Your Website From Crashing Saad Khan 2025-01-07T14:00:00+00:00 2025-01-07T22:04:48+00:00 This article is sponsored by Cloudways Product launches and sales typically attract large volumes of traffic.
To extend Dynatrace diagnostic visibility into network traffic, we’ve added out-of-the-box DNS request tracking to our infrastructure monitoring capabilities. While our competitors only provide generic traffic monitoring without artificial intelligence, Dynatrace automatically analyzes DNS-related anomalies.
By providing a dedicated service layer to facilitate service discovery and how applications share information with each other, they provide security, tracing, monitoring, and traffic control.
API resilience is about creating systems that can recover gracefully from disruptions, such as network outages or sudden traffic spikes, ensuring they remain reliable and secure. This has become critical since APIs serve as the backbone of todays interconnected systems.
For example, if you’re monitoring network traffic and the average over the past 7 days is 500 Mbps, the threshold will adapt to this baseline. An anomaly will be identified if traffic suddenly drops below 200 Mbps or above 800 Mbps, helping you identify unusual spikes or drops.
Therefore, real online traffic is crucial for server-side testing. TCPCopy [1] is an open-source traffic replay tool that has been widely adopted by large enterprises. It is now difficult to rely solely on the personal experience of developers or testers to cover all possible business scenarios.
Network traffic power calculations rely on static power estimations for both public and private networks. Static assumptions are: Local network traffic uses 0.12 Public network traffic uses 1.0 These estimates are converted using the emission factor for the data center location.
We have developed a microservices architecture platform that encounters sporadic system failures when faced with heavy traffic events. System resilience stands as the key requirement for e-commerce platforms during scaling operations to keep services operational and deliver performance excellence to users.
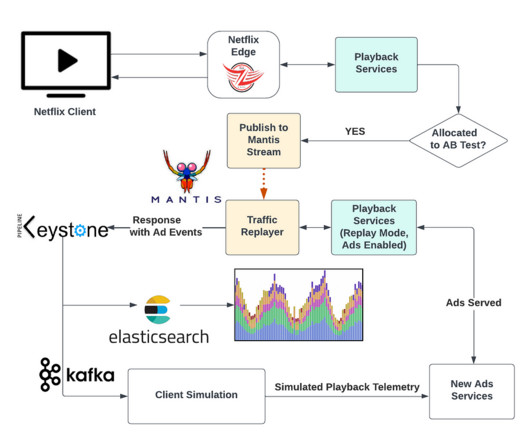
To do this, we devised a novel way to simulate the projected traffic weeks ahead of launch by building upon the traffic migration framework described here. New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing.
To detect issues proactively, we need to simulate traffic and predict system behavior in advance. Once artificial traffic is generated, discarding the response object and relying solely on logs becomes inefficient.
Accurately Reflecting Production Behavior A key part of our solution is insights into production behavior, which necessitates our requests to the endpoint result in traffic to the real service functions that mimics the same pathways the traffic would take if it came from the usualcallers. We call this capability TimeTravel.
A sudden spike in traffic caused Lambda timeouts, API Gateway threw 5xx errors, and customers started tweeting, Why cant I check out?! Our "serverless" order processing system built on AWS Lambda and API Gateway was humming along, handling 1,000 transactions/minute. Then, disaster struck.
The control group’s traffic utilized the legacy Falcor stack, while the experiment population leveraged the new GraphQL client and was directed to the GraphQL Shim. This helped us successfully migrate 100% of the traffic on the mobile homepage canvas to GraphQL in 6 months. After validating performance, we slowly built up scope.
Scaling RabbitMQ ensures your system can handle growing traffic and maintain high performance. Optimizing RabbitMQ performance through strategies such as keeping queues short, enabling lazy queues, and monitoring health checks is essential for maintaining system efficiency and effectively managing high traffic loads.
In the past 15+ years, online video traffic has experienced a dramatic boom utterly unmatched by any other form of content. It must be said that this video traffic phenomenon primarily owes itself to modernizations in the scalability of streaming infrastructure, which simply weren’t present fifteen years ago.
Systems that operate at a cloud scale can get expected or unexpected surges of traffic from one or multiple callers and are expected to perform in a predictable manner. This article analyzes the effects of traffic surges on a distributed system.
While most government agencies and commercial enterprises have digital services in place, the current volume of usage — including traffic to critical employment, health and retail/eCommerce services — has reached levels that many organizations have never seen before or tested against. So how do you know what to prepare for?
This article provides an overview of Azure's load balancing options, encompassing Azure Load Balancer, Azure Application Gateway, Azure Front Door Service, and Azure Traffic Manager. Each of these services addresses specific use cases, offering diverse functionalities to meet the demands of modern applications.
Service meshes are becoming increasingly popular in cloud-native applications as they provide a way to manage network traffic between microservices. It offers several features, including: Prioritized load shedding: Drops traffic that is deemed less important to ensure that the most critical traffic is served.
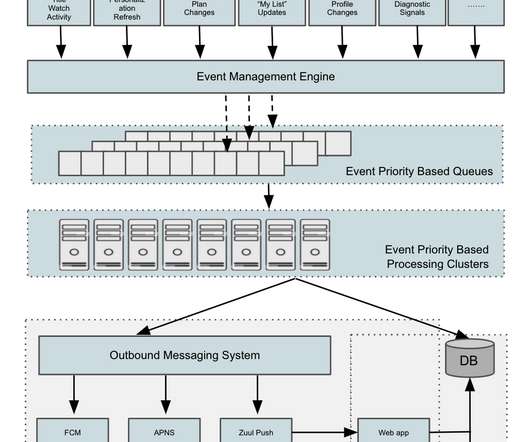
We thus assigned a priority to each use case and sharded event traffic by routing to priority-specific queues and the corresponding event processing clusters. This separation allows us to tune system configuration and scaling policies independently for different event priorities and traffic patterns.
Over the last two month s, w e’ve monito red key sites and applications across industries that have been receiving surges in traffic , including government, health insurance, retail, banking, and media. The following day, a normally mundane Wednesday , traffic soared to 128,000 sessions. Media p erformance .
In my last blog , I’ve provided an example of this happening, whereby the traffic spiked and quadrupled the usual incoming traffic. These are all interesting metrics from marketing point of view, and also highly interesting to you as they allow you to engage with the teams that are driving the traffic against your IT-system.
How viewers are able to watch their favorite show on Netflix while the infrastructure self-recovers from a system failure By Manuel Correa , Arthur Gonigberg , and Daniel West Getting stuck in traffic is one of the most frustrating experiences for drivers around the world. Logs and background requests are examples of this type of traffic.
Let us consider two scenarios where website traffic may increase: The goal of this kind of testing is to measure the error handling capabilities of the software to ensure that it does not crash under extremely heavy load conditions.
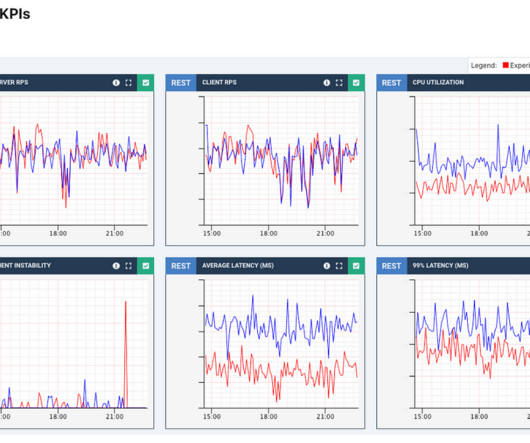
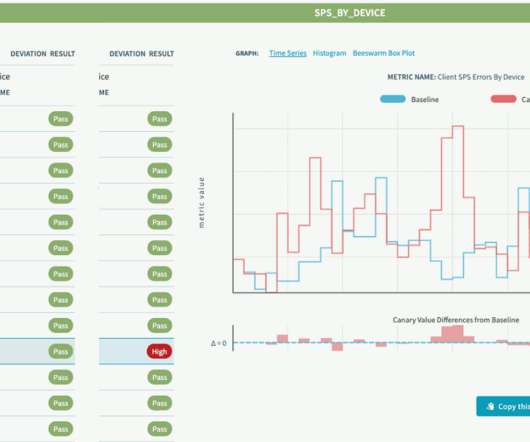
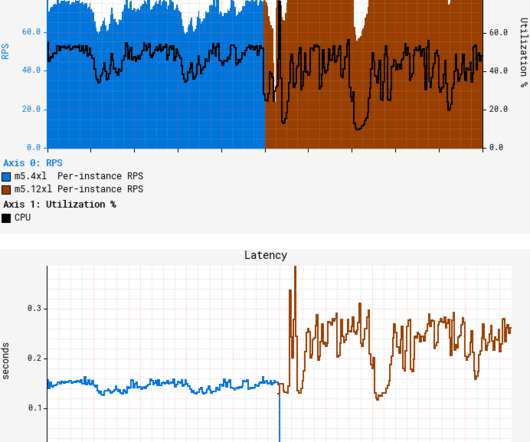
A quick canary test was free of errors and showed lower latency, which is expected given that our standard canary setup routes an equal amount of traffic to both the baseline running on 4xl and the canary on 12xl. What’s worse, average latency degraded by more than 50%, with both CPU and latency patterns becoming more “choppy.”
With the advent of cloud computing, managing network traffic and ensuring optimal performance have become critical aspects of system architecture. Amazon Web Services (AWS), a leading cloud service provider, offers a suite of load balancers to manage network traffic effectively for applications running on its platform.
Envoy proxy, the data plane of Istio service mesh, is used for handling east-west traffic ( service-to-service communication within a data center). However, to make Istio manage a network of multicloud applications, Envoy was configured as a sidecar proxy for handling north-south traffic (traffic in and out of data centers).
Even when the staging environment closely mirrors the production environment, achieving a complete replication of all potential scenarios, such as simulating extremely high traffic volumes to assess software performance, remains challenging. This can lead to a lack of insight into how the code will behave when exposed to heavy traffic.
Aside from the huge surge in internal application usage, businesses are also witnessing increased levels of user traffic to their applications. Facilitating an understanding of traffic patterns and potential traffic spikes helps maintain customer experience. One example of these surges was from an unemployment application.
Unnecessary traffic between such data centers can result in wasted resources, unpredictable downtimes, and lost business. By minimizing bandwidth and preventing unrelated traffic between data centers, you can maintain healthy network infrastructure and save on costs. optimizing traffic routing.
This becomes even more challenging when the application receives heavy traffic, because a single microservice might become overwhelmed if it receives too many requests too quickly. The Envoy proxies also collect and report telemetry on all traffic among the services in the mesh. Why do you need a service mesh?
This open-source software, lauded for its reliability and high performance, is a vital tool in the arsenal of network administrators, adept at managing web traffic across diverse server environments. When traffic to a website or application increases, HAProxy can seamlessly bring more servers online to handle the load.
The F5 BIG-IP Local Traffic Manager (LTM) is an application delivery controller (ADC) that ensures the availability, security, and optimal performance of network traffic flows. Detect and respond to security threats like DDoS attacks or web application attacks by monitoring application traffic and logs.
Statista shares insightful data on mobile web traffic that accounts for more than 50% globally from 1st quarter 2015 to 3rd quarter 2020. This increase in web traffic from mobile users comes with an expectation.
For example, you can monitor the behavior of your applications, the hardware usage of your server nodes, or even the network traffic between servers. And there are a lot of monitoring tools available providing all kinds of features and concepts.
Putting an external cache in front of the database is commonly used to compensate for subpar latency stemming from various factors, such as inefficient database internals, driver usage, infrastructure choices, traffic spikes, and so on.
With Dynatrace OneAgent you also benefit from support for traffic routing and traffic control. OneAgent implements network zones to create traffic routing rules and limit cross data-center traffic. Upgrade OpenTracing instrumentation with high-fidelity data provided by OneAgent.
This opens the door to auto-scalable applications, which effortlessly matches the demands of rapidly growing and varying user traffic. Containers can be replicated or deleted on the fly to meet varying end-user traffic. In production, containers are easy to replicate. What is Docker? Networking.
We organize all of the trending information in your field so you don't have to. Join 5,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content