
Consistent caching mechanism in Titus Gateway
The Netflix TechBlog
NOVEMBER 3, 2022
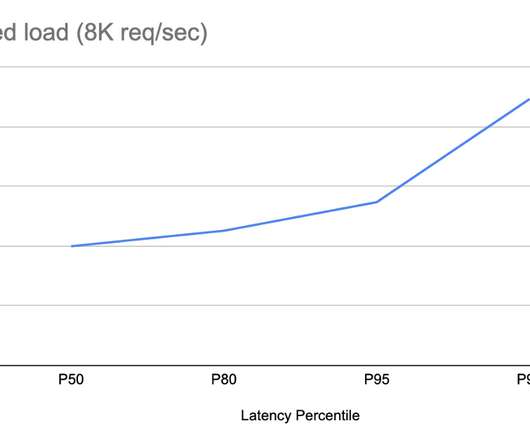
In that scenario, the system would need to deal with the data propagation latency directly, for example, by use of timeouts or client-originated update tracking mechanisms. With traffic growth, a single leader node handling all request volume started becoming overloaded. The cache is kept in sync with the current leader process.








































Let's personalize your content