
Native App Network Performance Analysis
DZone
APRIL 7, 2021
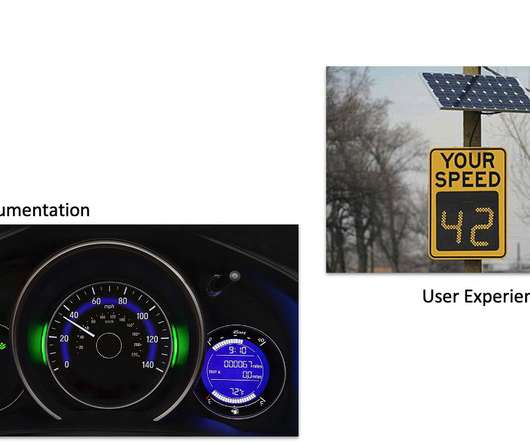
When 54 percent of the internet traffic share is accounted for by Mobile , it's certainly nontrivial to acknowledge how your app can make a difference to that of the competitor! Introduction.





















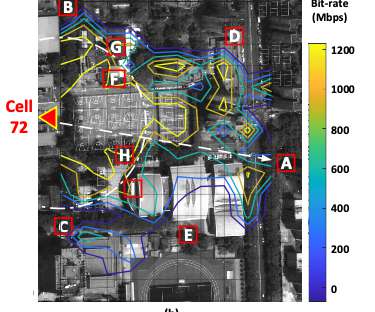

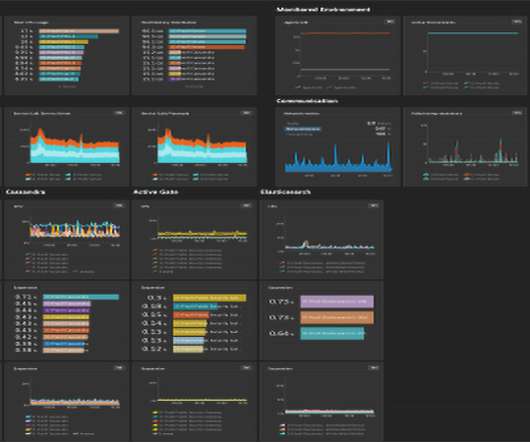





















Let's personalize your content