

Best practices and key metrics for improving mobile app performance
Dynatrace
DECEMBER 13, 2023
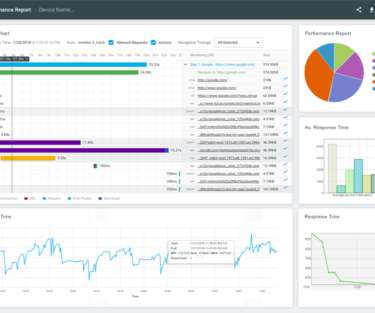
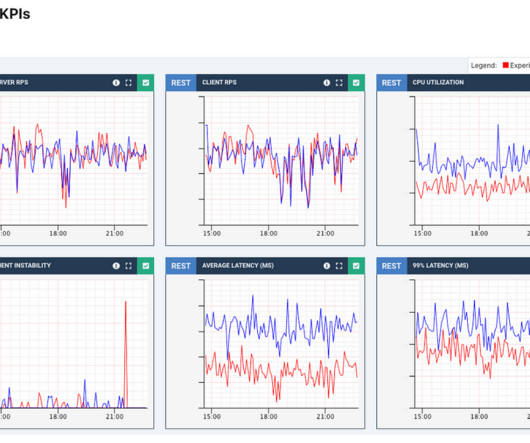
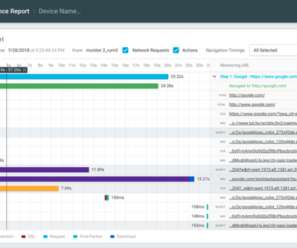
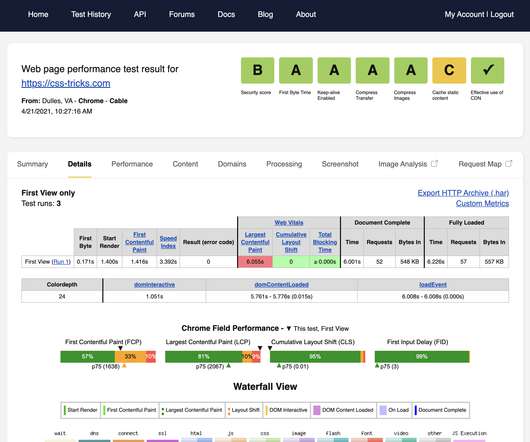
By monitoring metrics such as error rates, response times, and network latency, developers can identify trends and potential issues, so they don’t become critical. Load time and network latency metrics. Minimizing the number of network requests that your app makes can improve performance by reducing latency and improving load times.




































Let's personalize your content