

Kubernetes in the wild report 2023
Dynatrace
JANUARY 16, 2023
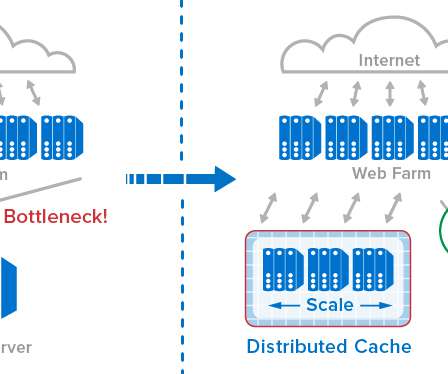
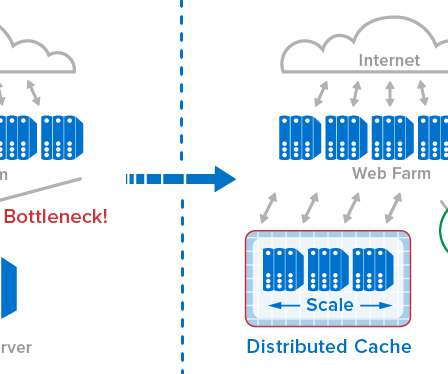
The report also reveals the leading programming languages practitioners use for application workloads. are the top 3 programming languages for Kubernetes application workloads. Of the organizations in the Kubernetes survey, 71% run databases and caches in Kubernetes, representing a +48% year-over-year increase.































Let's personalize your content