

MySQL on Azure Performance Benchmark – ScaleGrid vs. Azure Database
Scalegrid
AUGUST 26, 2020
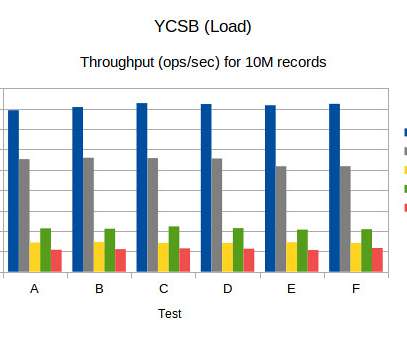
ScaleGrid MySQL on Azure so you can see which provider offers the best throughput and latency performance. We measure latency in ms 95th percentile latency. During Read-Intensive Workloads, ScaleGrid manages to achieve up to 3 times higher throughput and averages 66% better latency compared to Azure Database.






























Let's personalize your content