

Dynatrace observability is now available for Red Hat OpenShift on the IBM® Power® architecture
Dynatrace
JULY 11, 2023
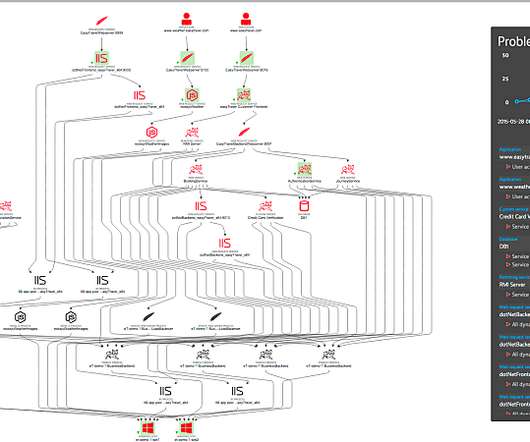
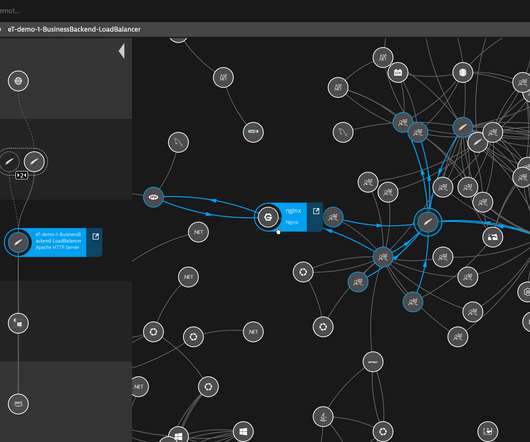
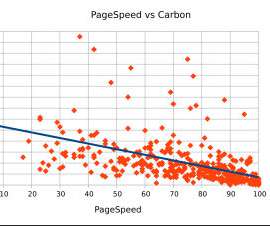
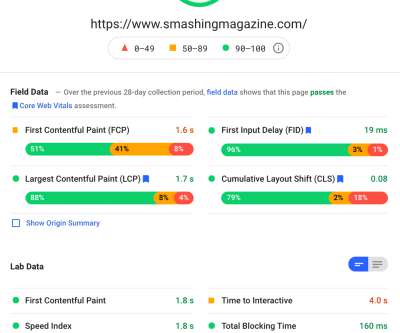
By leveraging the Dynatrace Operator and Dynatrace capabilities on Red Hat OpenShift on IBM Power, customers can accelerate their modernization to hybrid cloud and increase operational efficiencies with greater visibility across the full stack from hardware through application processes.




































Let's personalize your content