

Why IT Needs to Look at the Network Through a 4-D Lens
DZone
SEPTEMBER 9, 2019
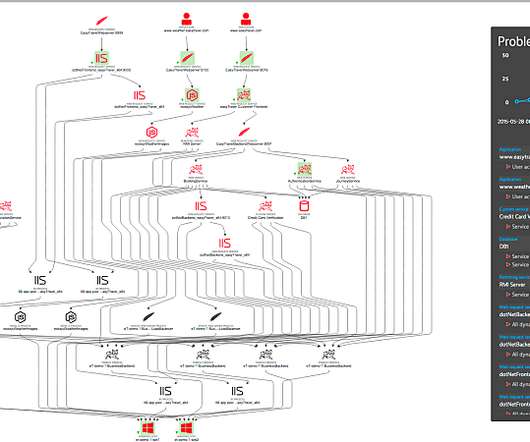
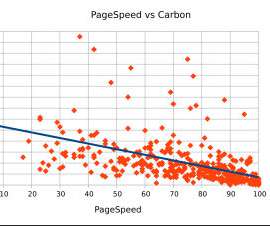
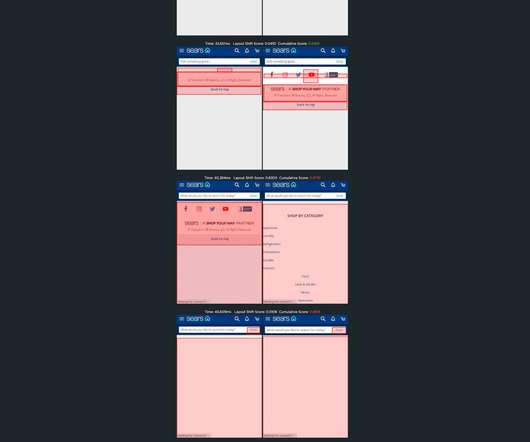
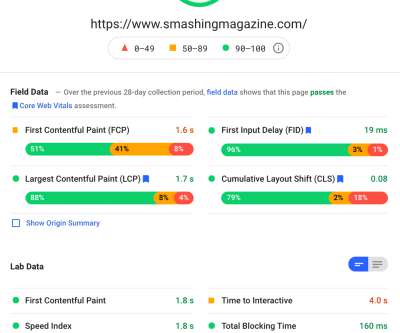
Someone trying to look at the network through a 4-D lens. While ‘digital transformation’ and ‘cloud migration’ are two concepts with relatively broad definitions, they’re both rooted in the modernization of enterprise networks.































Let's personalize your content