

Essential Guidelines for Building Optimized ETL Data Pipelines in the Cloud With Azure Data Factory
DZone
AUGUST 14, 2024
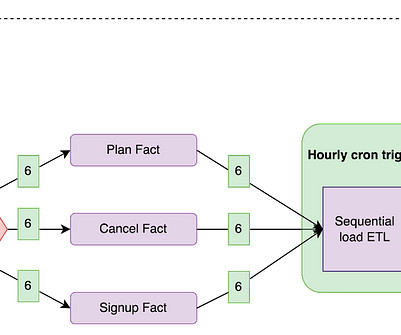
When building ETL data pipelines using Azure Data Factory (ADF) to process huge amounts of data from different sources, you may often run into performance and design-related challenges. This article will serve as a guide in building high-performance ETL pipelines that are both efficient and scalable.









































Let's personalize your content