

Dynatrace accelerates business transformation with new AI observability solution
Dynatrace
JANUARY 31, 2024
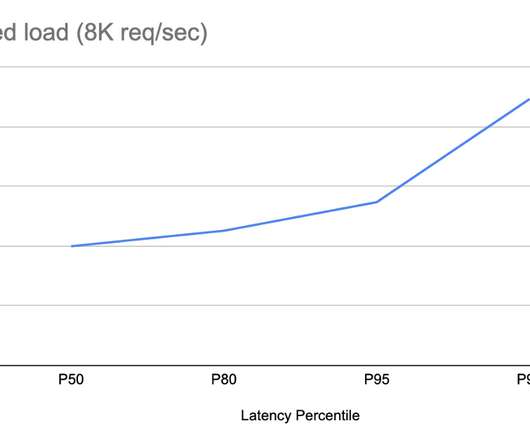
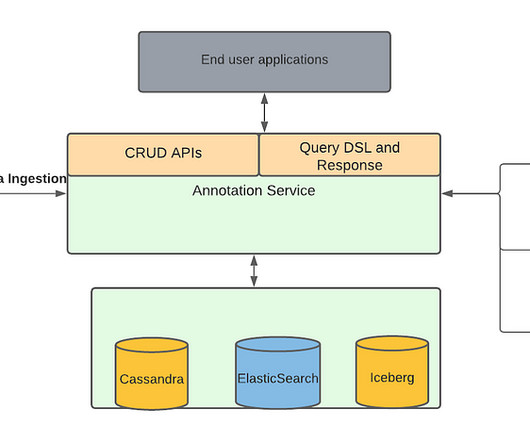
While off-the-shelf models assist many organizations in initiating their journeys with generative AI (GenAI), scaling AI for enterprise use presents formidable challenges. However, RAG is not perfect and raises various challenges, particularly concerning the use of vector databases and semantic caches.







































Let's personalize your content