
Cloud infrastructure monitoring in action: Dynatrace on Dynatrace
Dynatrace
SEPTEMBER 29, 2020
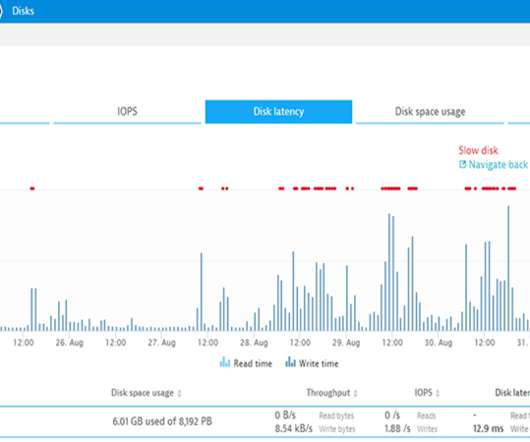
Since we moved to AWS in May 2014 we have had an availability of 99.95%! Sydney, we have a disk write latency problem! It was on August 25 th at 14:00 when Davis initially alerted on a disk write latency issues to Elastic File System (EFS) on one of our EC2 instances in AWS’s Sydney Data Center.








































Let's personalize your content