

Why applying chaos engineering to data-intensive applications matters
Dynatrace
MAY 23, 2024
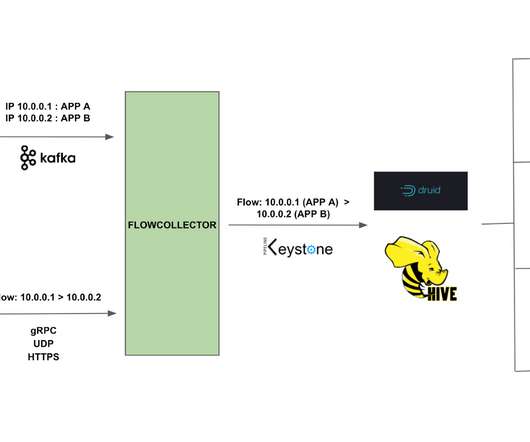
Such frameworks support software engineers in building highly scalable and efficient applications that process continuous data streams of massive volume. The following are key insights from our extensive experimental analysis: Flink, Kafka Streams, and Spark Structured Streaming are resilient to different types and degrees of failure.











































Let's personalize your content