

Driving your FinOps strategy with observability best practices
Dynatrace
MARCH 18, 2024
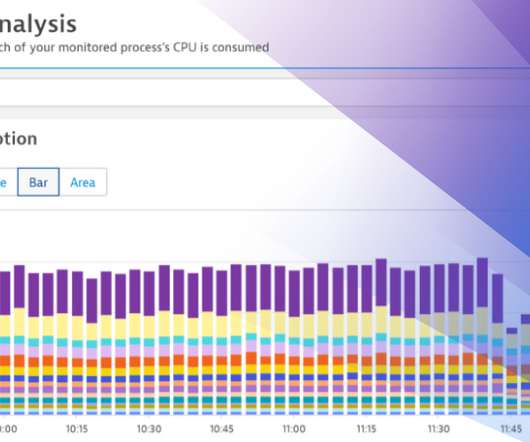
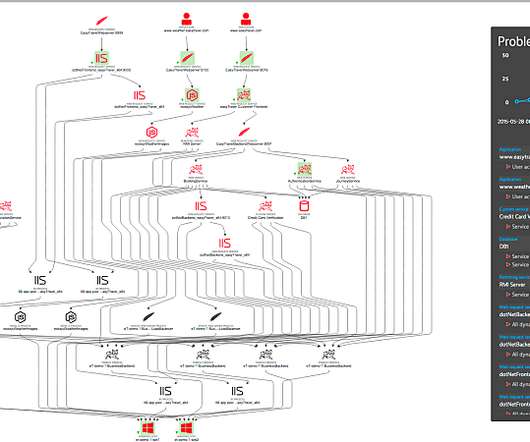
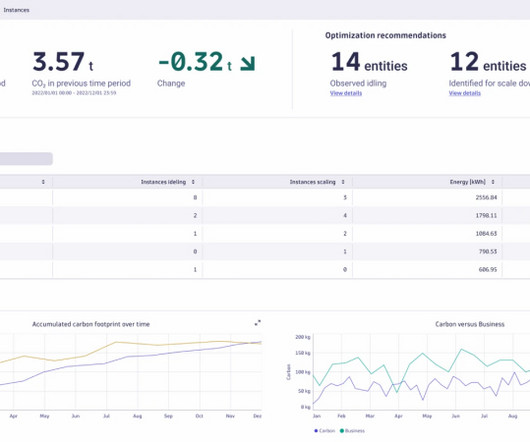
In response, many organizations are adopting a FinOps strategy. Empowering teams to manage their FinOps practices, however, requires teams to have access to reliable multicloud monitoring and analysis data. Dynatrace can help you achieve your FinOps strategy using observability best practices.











































Let's personalize your content