

What is a Distributed Storage System
Scalegrid
FEBRUARY 8, 2024
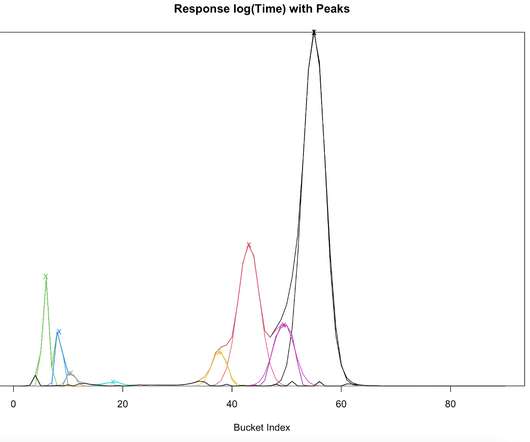
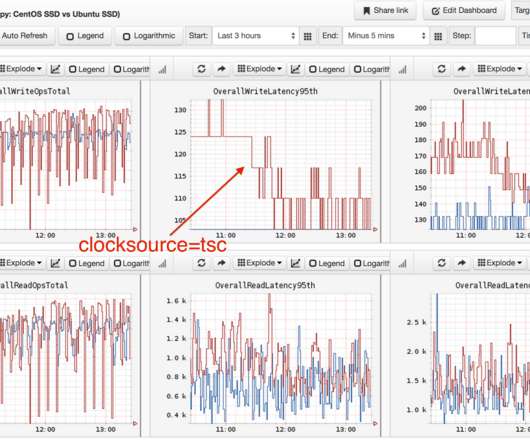
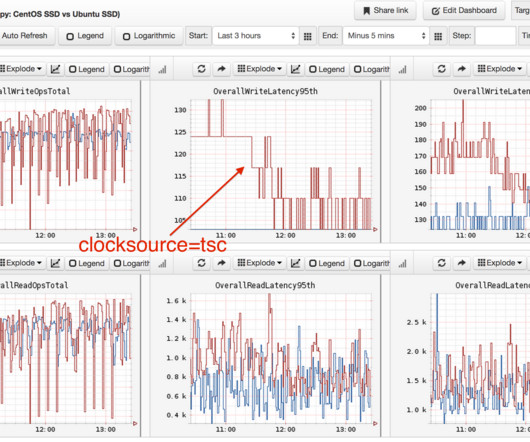
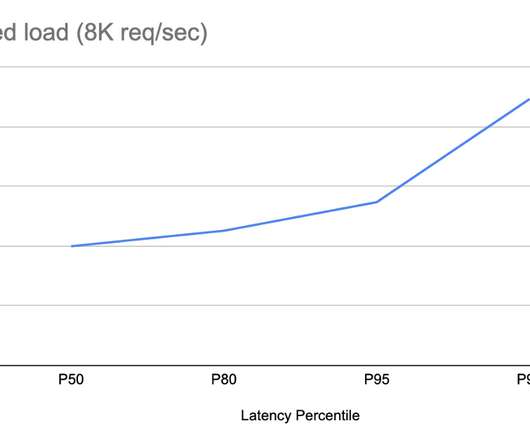
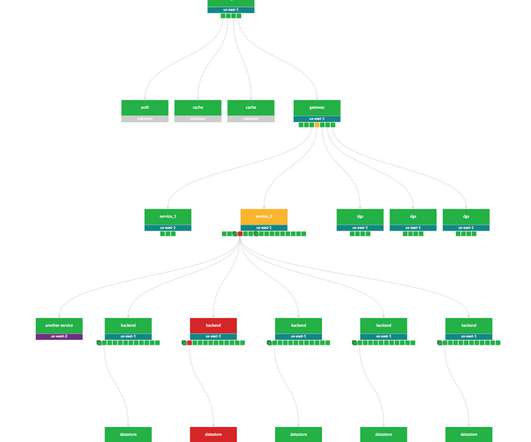
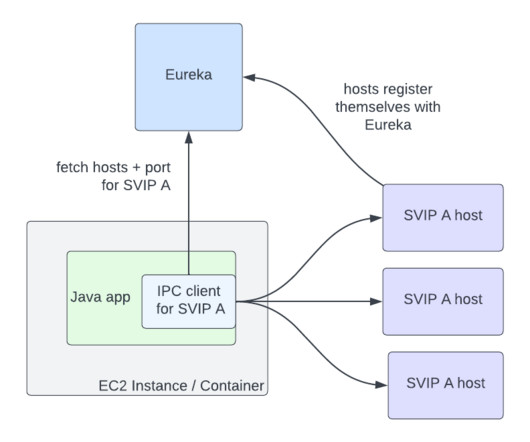
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.




































Let's personalize your content