Architectural Insights: Designing Efficient Multi-Layered Caching With Instagram Example
DZone
FEBRUARY 27, 2024
Leveraging this hierarchical structure can significantly reduce latency and improve overall performance.
 Efficiency Example Latency Systems
Efficiency Example Latency Systems 
DZone
FEBRUARY 27, 2024
Leveraging this hierarchical structure can significantly reduce latency and improve overall performance.
The Netflix TechBlog
SEPTEMBER 29, 2022
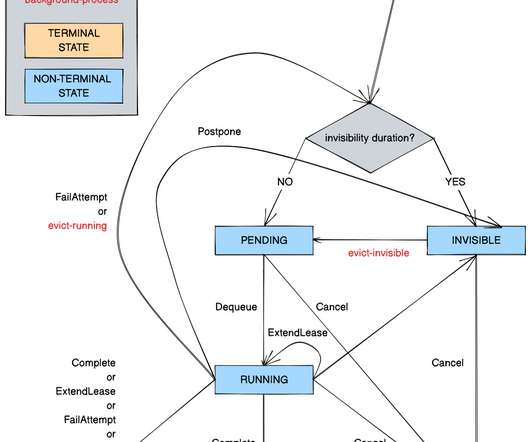
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

The Netflix TechBlog
MARCH 7, 2024
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems. For many of our applications, model explainability matters.
Dynatrace
FEBRUARY 21, 2024
Quality gates examples in Dynatrace Quality gates hold much promise for organizations looking to release better software faster. The following are specific examples that demonstrate quality gates in action: Security gates Security gates ensure code meets key security requirements defined by development and security stakeholders.

Scalegrid
JANUARY 25, 2024
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. These essential data points heavily influence both stability and efficiency within the system.

Dynatrace
SEPTEMBER 13, 2023
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.

Dynatrace
JANUARY 31, 2024
GenAI is prone to erratic behavior due to unforeseen data scenarios or underlying system issues. For example, a Stanford University and UC Berkeley team noted in a research study that ChatGPT behavior deteriorates over time. For example, generating an image requires as much power as fully charging your smartphone.

Expert insights. Personalized for you.





































Let's personalize your content