

How observability, application security, and AI enhance DevOps and platform engineering maturity
Dynatrace
APRIL 18, 2024
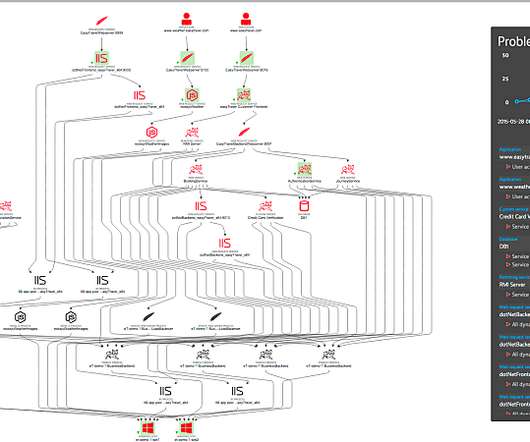
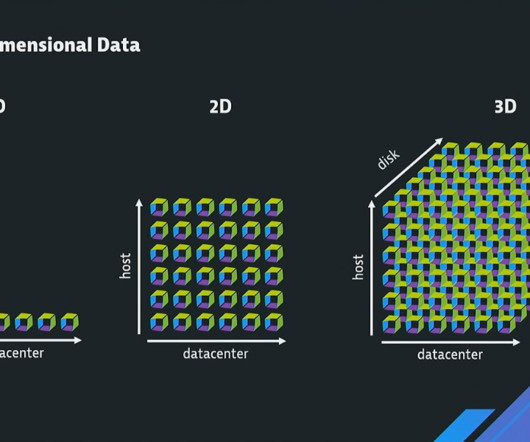
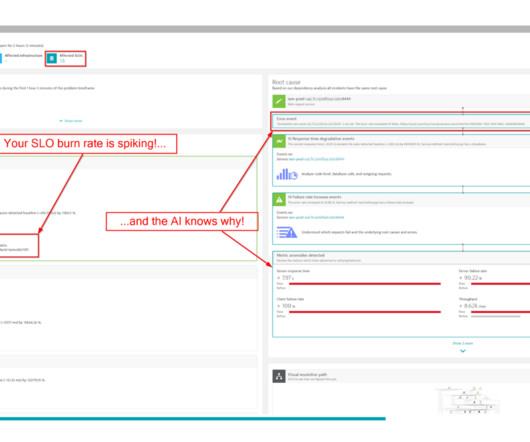
DevOps and platform engineering are essential disciplines that provide immense value in the realm of cloud-native technology and software delivery. Observability of applications and infrastructure serves as a critical foundation for DevOps and platform engineering, offering a comprehensive view into system performance and behavior.














































Let's personalize your content