

Extract metrics from business events to increase the value of business analytics
Dynatrace
FEBRUARY 2, 2023
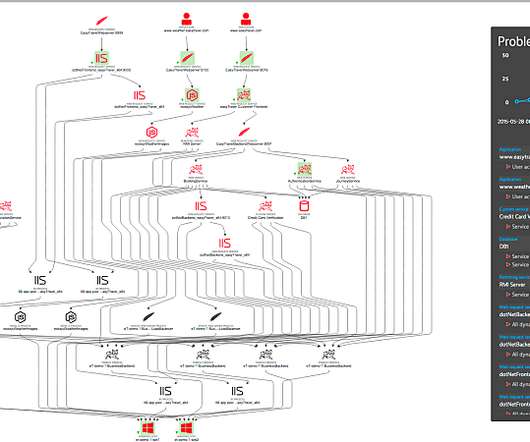
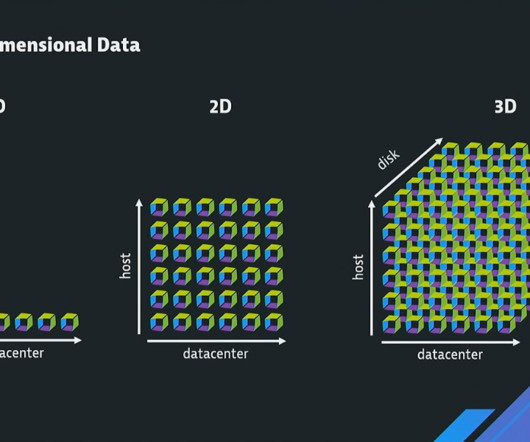
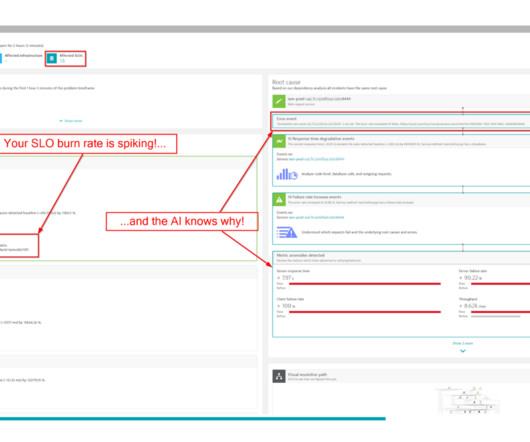
Observability fault lines The monitoring of complex and dynamic IT systems includes real-time analysis of baselines, trends, and anomalies. This is achieved, in part, by establishing actionable statistical accuracy —not necessarily precise accuracy —through practical levels of metric sampling, aggregation, and extrapolation.













































Let's personalize your content