
Data Reprocessing Pipeline in Asset Management Platform @Netflix
The Netflix TechBlog
MARCH 10, 2023
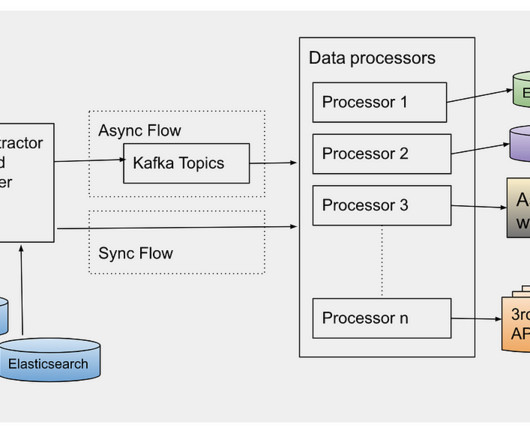
Hence we built the data pipeline that can be used to extract the existing assets metadata and process it specifically to each new use case. This feature support required a significant update in the data table design (which includes new tables and updating existing table columns). N, first N rows are fetched from the table.












































Let's personalize your content