

SLOs done right: how DevOps teams can build better service-level objectives
Dynatrace
MARCH 16, 2023
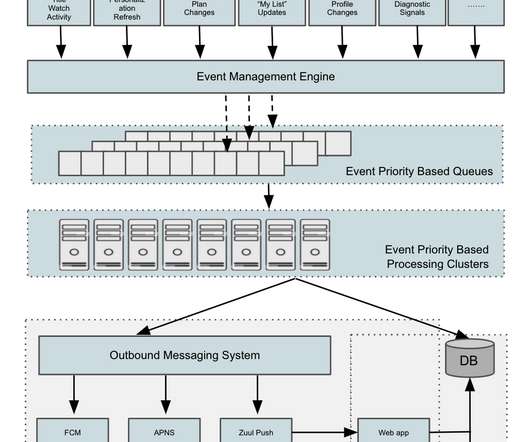
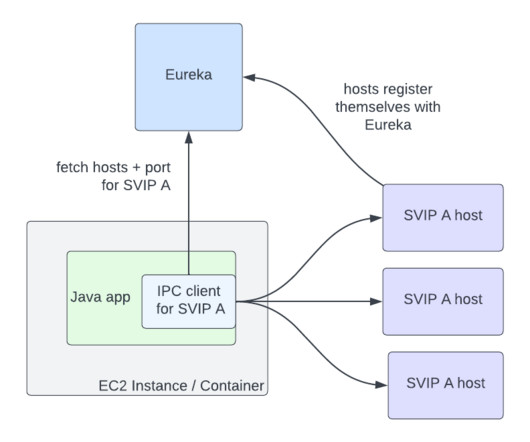
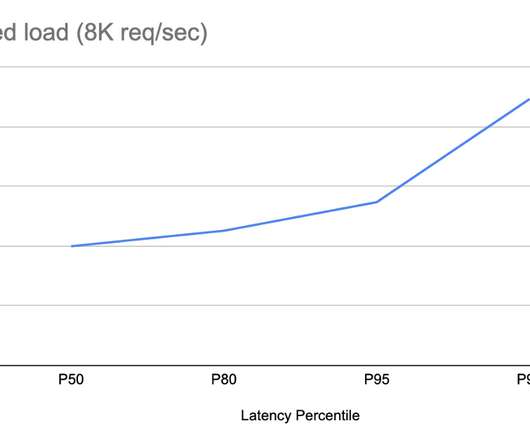
So how do development and operations (DevOps) teams and site reliability engineers (SREs) distinguish among good, great, and suboptimal SLOs? Monitors signals The first attribute of a good SLO is the ability to monitor the four “golden signals”: latency, traffic, error rates, and resource saturation.




































Let's personalize your content