

FIFO vs. LIFO: Which Queueing Strategy Is Better for Availability and Latency?
DZone
MARCH 14, 2023
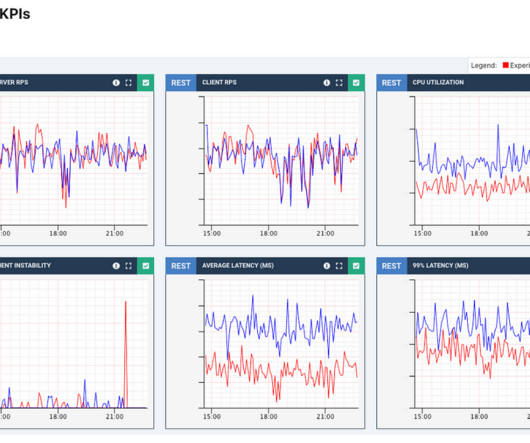
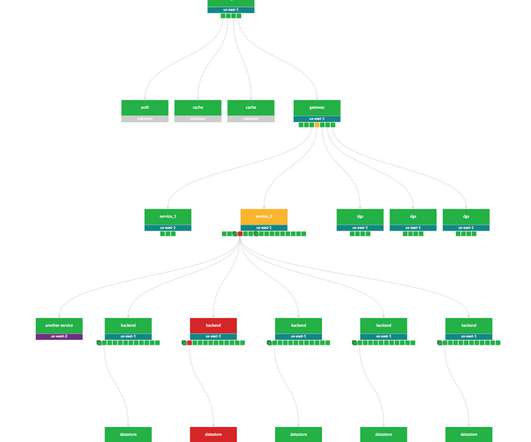
As an engineer, you probably know that server performance under heavy load is crucial for maintaining the availability and responsiveness of your services. But what happens when traffic bursts overwhelm your system? Queueing requests is a common solution, but what's the best approach: FIFO or LIFO?








































Let's personalize your content