Architectural Insights: Designing Efficient Multi-Layered Caching With Instagram Example
DZone
FEBRUARY 27, 2024
Leveraging this hierarchical structure can significantly reduce latency and improve overall performance.
 Design Efficiency Latency Systems
Design Efficiency Latency Systems 
DZone
FEBRUARY 27, 2024
Leveraging this hierarchical structure can significantly reduce latency and improve overall performance.
The Netflix TechBlog
SEPTEMBER 29, 2022
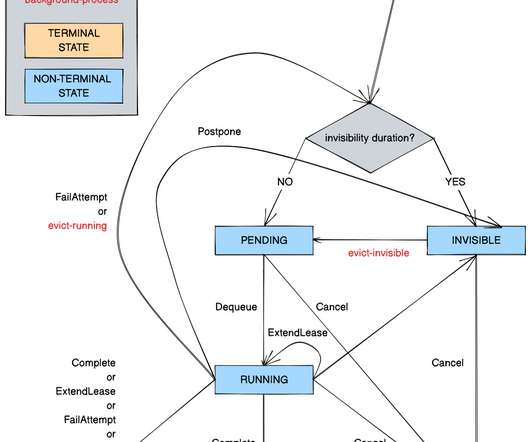
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

The Netflix TechBlog
MARCH 7, 2024
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems. ETL workflows), as well as downstream (e.g.

DZone
JUNE 22, 2023
It involves a combination of techniques and best practices aimed at reducing latency, improving user experience, and increasing the overall efficiency of the system. API performance optimization is the process of improving the speed, scalability, and reliability of APIs.

Scalegrid
FEBRUARY 8, 2024
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.

Scalegrid
JANUARY 25, 2024
Key Takeaways Critical performance indicators such as latency, CPU usage, memory utilization, hit rate, and number of connected clients/slaves/evictions must be monitored to maintain Redis’s high throughput and low latency capabilities. These essential data points heavily influence both stability and efficiency within the system.

Dynatrace
SEPTEMBER 13, 2023
This is a set of best practices and guidelines that help you design and operate reliable, secure, efficient, cost-effective, and sustainable systems in the cloud. The framework comprises six pillars: Operational Excellence, Security, Reliability, Performance Efficiency, Cost Optimization, and Sustainability.

Expert insights. Personalized for you.



































Let's personalize your content