
Seamless offloading of web app computations from mobile device to edge clouds via HTML5 Web Worker migration
The Morning Paper
JANUARY 30, 2020
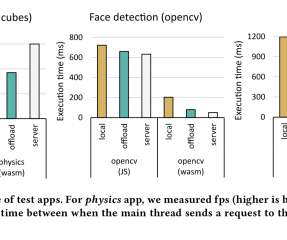
Edge servers are the middle ground – more compute power than a mobile device, but with latency of just a few ms. These use their regression models to estimate processing time (which will depend on the hardware available, current load, etc.). This could of course be a local worker on the mobile device.


























Let's personalize your content