
The Three Cs: Concatenate, Compress, Cache
CSS Wizardry
OCTOBER 16, 2023
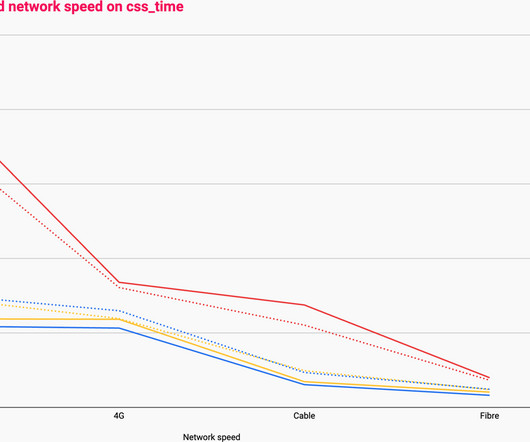
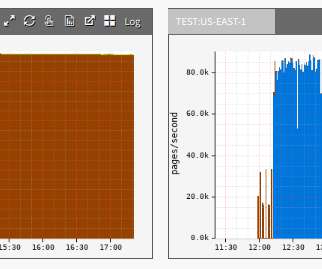
In this post, I’m going to break these processes down into each of: ? Caching them at the other end: How long should we cache files on a user’s device? Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. That’s almost 22× more!








































Let's personalize your content