

How Caches Become Databases – And Why You Don’t Want This
VoltDB
MARCH 21, 2024
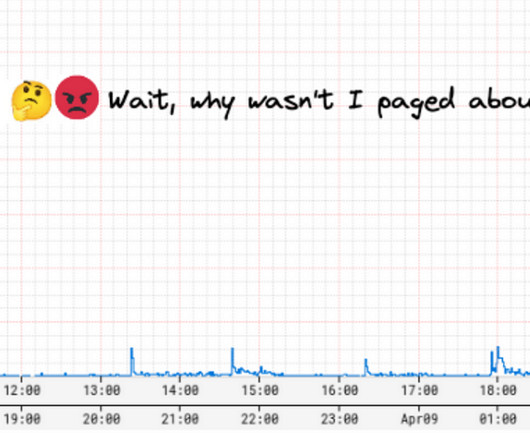
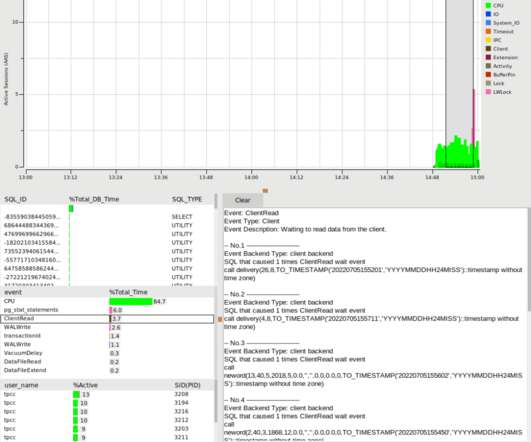
In the world of databases, data management, and data platforms, this entropy usually takes the form of a simple database or data platform that might be ideal for early use cases evolving (or rather, de volving) into an expensive and unmanageable nightmare due to operational strain from use-case gluttony. How hard can it be?






































Let's personalize your content