

How Amazon is solving big-data challenges with data lakes
All Things Distributed
JANUARY 20, 2020
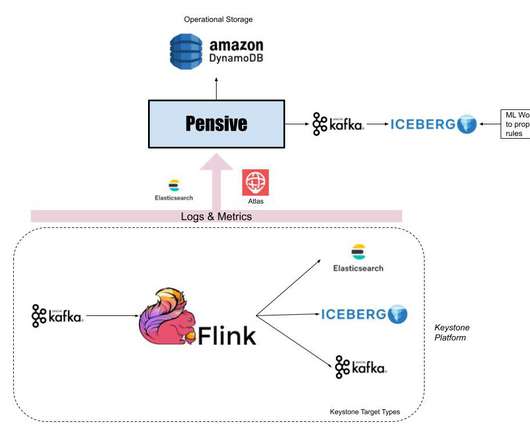
Amazon's worldwide financial operations team has the incredible task of tracking all of that data (think petabytes). At Amazon's scale, a miscalculated metric, like cost per unit, or delayed data can have a huge impact (think millions of dollars). The team is constantly looking for ways to get more accurate data, faster.







































Let's personalize your content