

What is Greenplum Database? Intro to the Big Data Database
Scalegrid
MAY 13, 2020
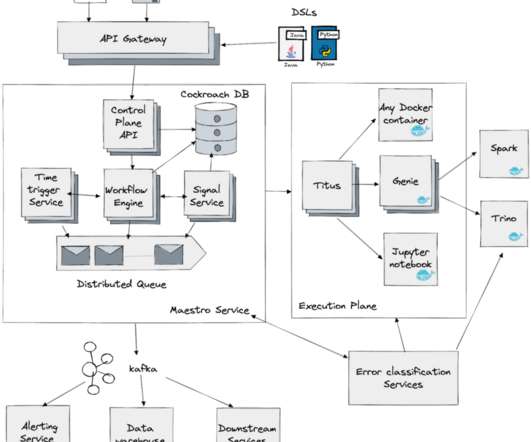
It can scale towards a multi-petabyte level data workload without a single issue, and it allows access to a cluster of powerful servers that will work together within a single SQL interface where you can view all of the data. This feature-packed database provides powerful and rapid analytics on data that scales up to petabyte volumes.

































Let's personalize your content