

FIFO vs. LIFO: Which Queueing Strategy Is Better for Availability and Latency?
DZone
MARCH 14, 2023
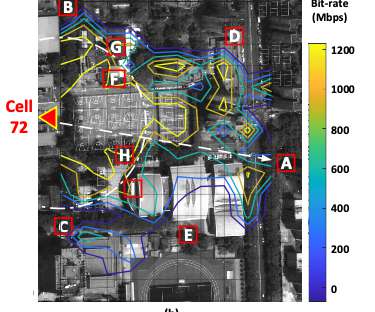
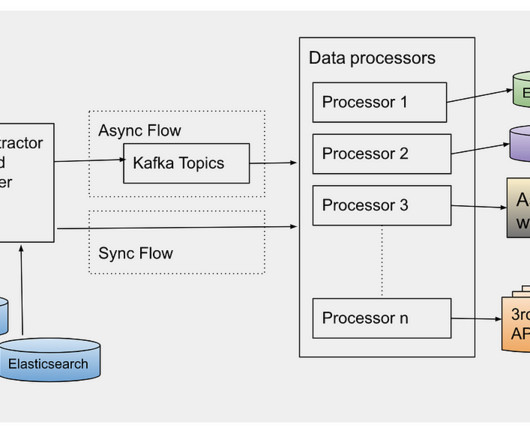
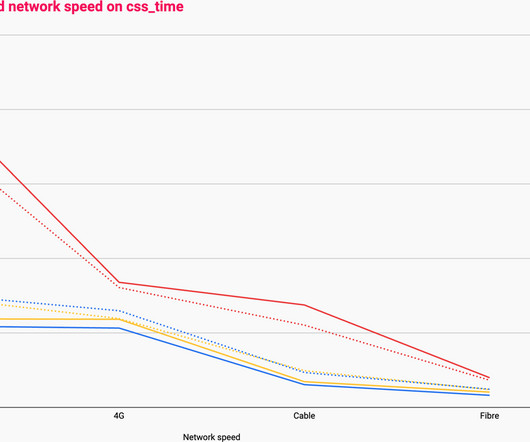
As an engineer, you probably know that server performance under heavy load is crucial for maintaining the availability and responsiveness of your services. In this post, we'll explore both strategies through a simple simulation in Colab, allowing you to see the impact of changing parameters on system performance.










































Let's personalize your content