
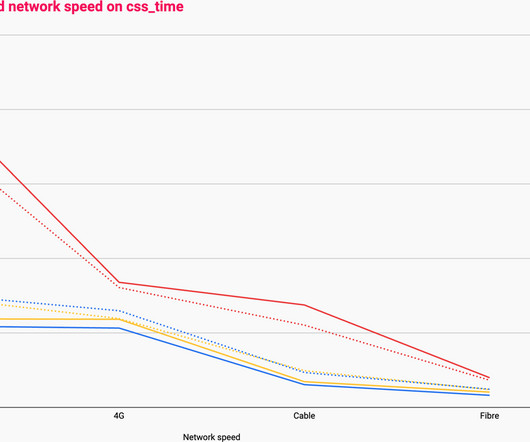
The Three Cs: Concatenate, Compress, Cache
CSS Wizardry
OCTOBER 16, 2023
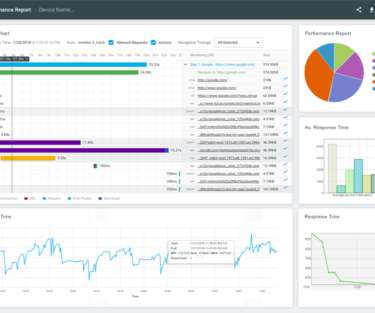
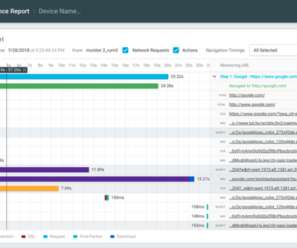
What is the availability, configurability, and efficacy of each? ?️ Plotted on the same horizontal axis of 1.6s, the waterfalls speak for themselves: 201ms of cumulative latency; 109ms of cumulative download. 4,362ms of cumulative latency; 240ms of cumulative download. And do any of our previous decisions dictate our options?







































Let's personalize your content