
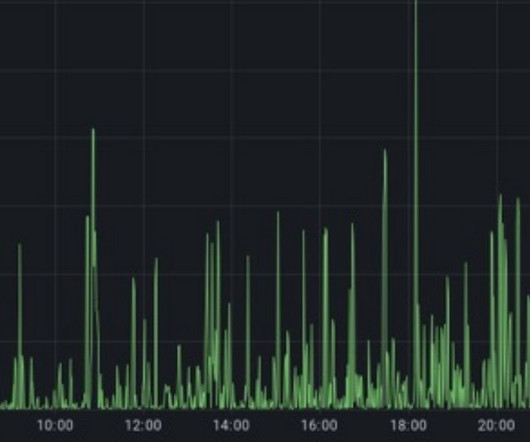
Allegro Reduces Kafka Producer Latency Outliers by 82% After Switching to XFS
InfoQ
APRIL 26, 2024
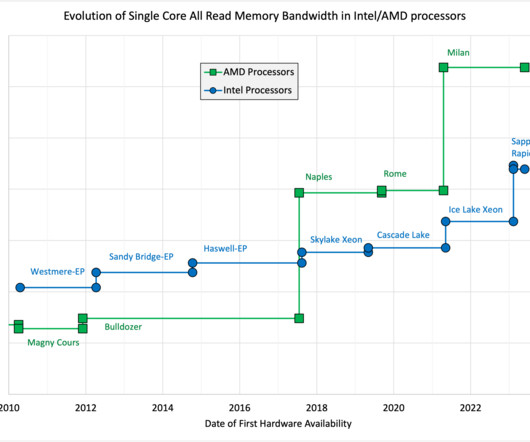
Allegro experimented with different performance optimization options to improve Apache Kafka producer tail latency and eventually switched all its clusters to the XFS filesystem. The company used Kafka protocol sniffing, JVM profiling, and eBPF, which proved instrumental in identifying and eliminating performance bottlenecks.





































Let's personalize your content