
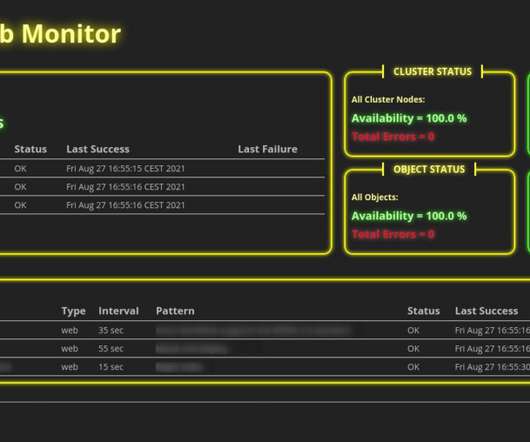
Monitoring Web Servers Should Never Be Complex
DZone
SEPTEMBER 29, 2021
If you run several web servers in your organization or even public web servers on the internet, you need some kind of monitoring. If your servers go down for some reason, this may not be funny for your colleagues, customer, and even for yourself. Introduction. For that reason, we use monitoring tools.








































Let's personalize your content