

Engineering dependability and fault tolerance in a distributed system
High Scalability
FEBRUARY 19, 2021
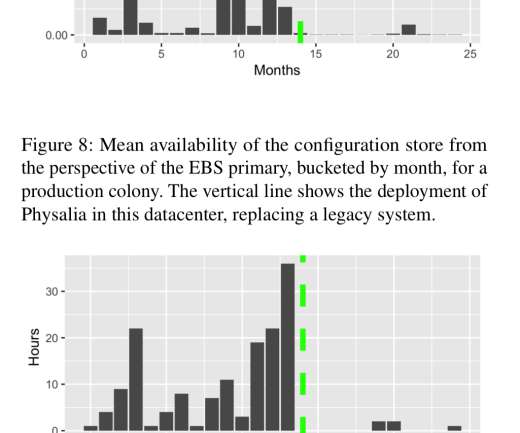
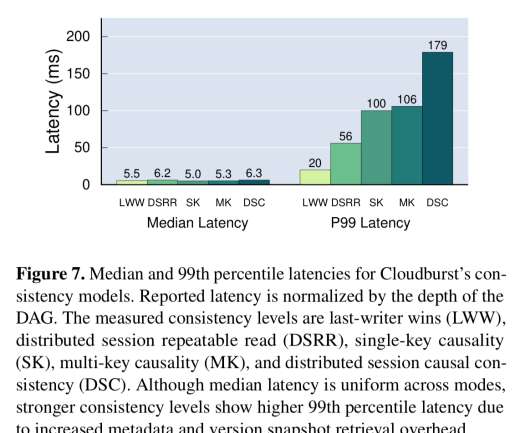
This means a system that is not merely available but is also engineered with extensive redundant measures to continue to work as its users expect. Fault tolerance The ability of a system to continue to be dependable (both available and reliable) in the presence of certain component or subsystem failures.










































Let's personalize your content