
Migrating Netflix to GraphQL Safely
The Netflix TechBlog
JUNE 14, 2023
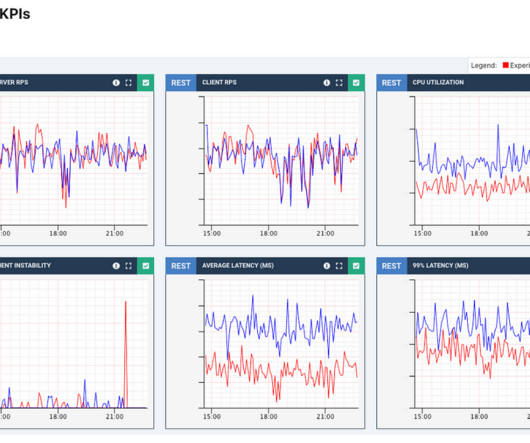
We migrated Netflix’s mobile apps to GraphQL with zero downtime, which involved a total overhaul from the client to the API layer. Until recently, an internal API framework, Falcor , powered our mobile apps. By the summer of 2020, many UI engineers were ready to move to GraphQL.


































Let's personalize your content