

Why applying chaos engineering to data-intensive applications matters
Dynatrace
MAY 23, 2024
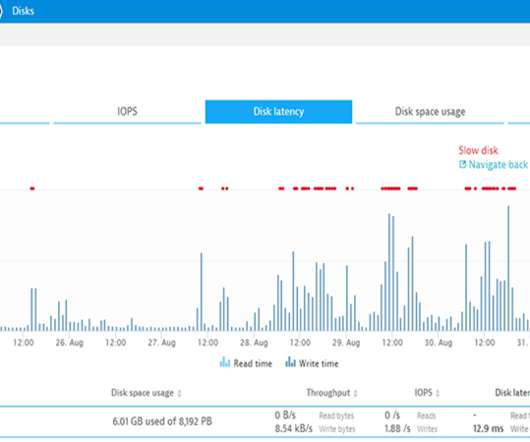
The jobs executing such workloads are usually required to operate indefinitely on unbounded streams of continuous data and exhibit heterogeneous modes of failure as they run over long periods. Failures can occur unpredictably across various levels, from physical infrastructure to software layers.













































Let's personalize your content