

Designing Instagram
High Scalability
JANUARY 11, 2022
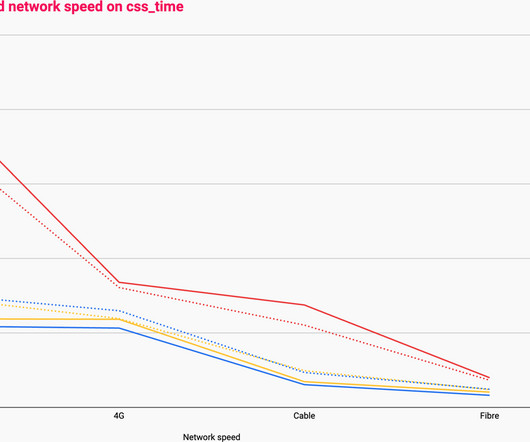
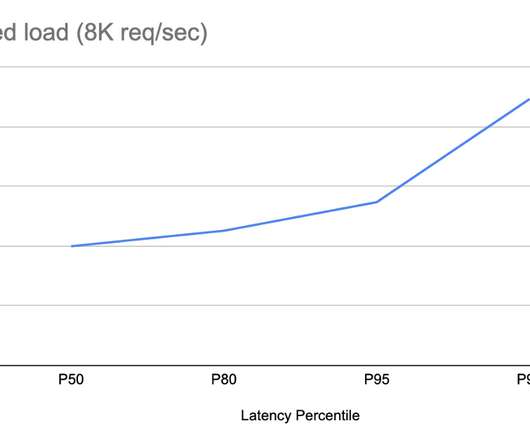
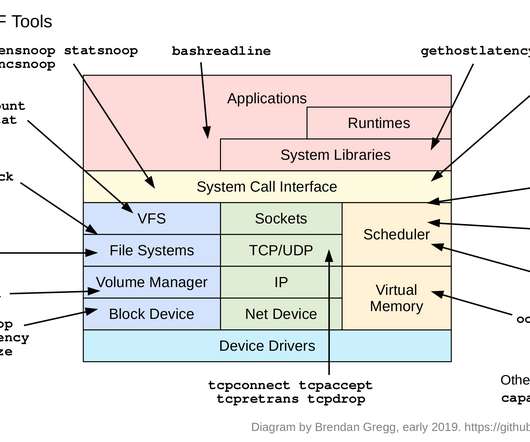
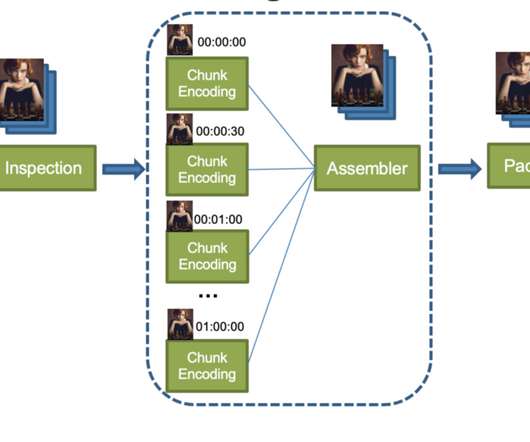
Design a photo-sharing platform similar to Instagram where users can upload their photos and share it with their followers. High Level Design. Component Design. There are two major processes which gets executed when a user posts a photo on Instagram. API Design. Problem Statement. Architecture.





































Let's personalize your content