

Data Reprocessing Pipeline in Asset Management Platform @Netflix
The Netflix TechBlog
MARCH 10, 2023
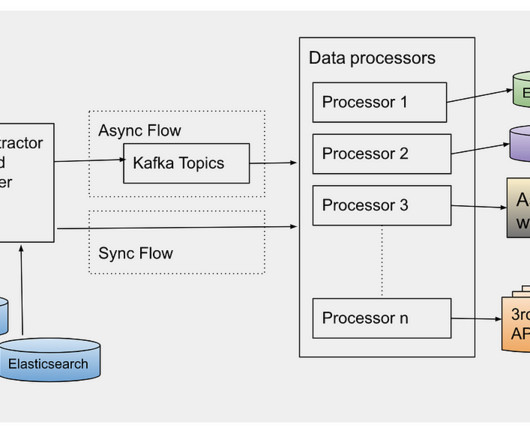
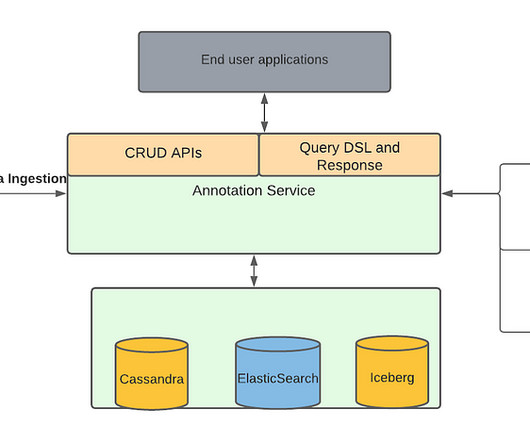
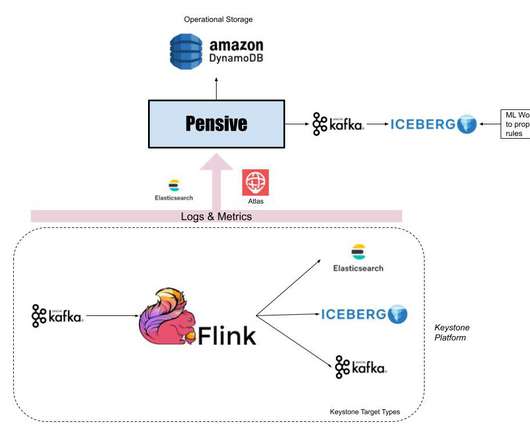
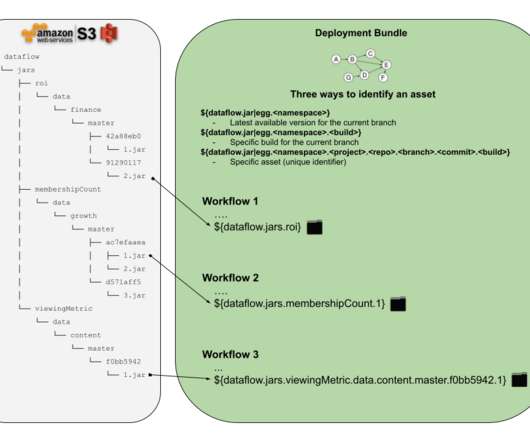
This platform has evolved from supporting studio applications to data science applications, machine-learning applications to discover the assets metadata, and build various data facts. Hence we built the data pipeline that can be used to extract the existing assets metadata and process it specifically to each new use case.




































Let's personalize your content