

Site reliability done right: 5 SRE best practices that deliver on business objectives
Dynatrace
MAY 31, 2023
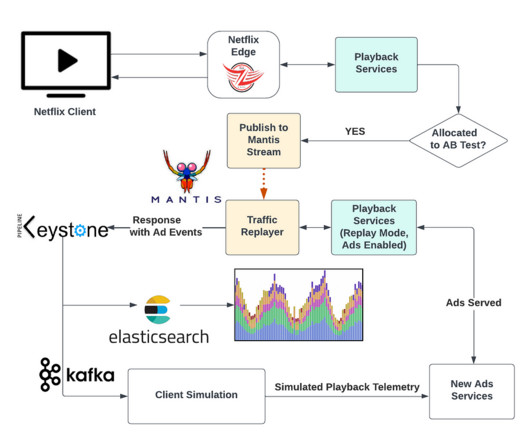
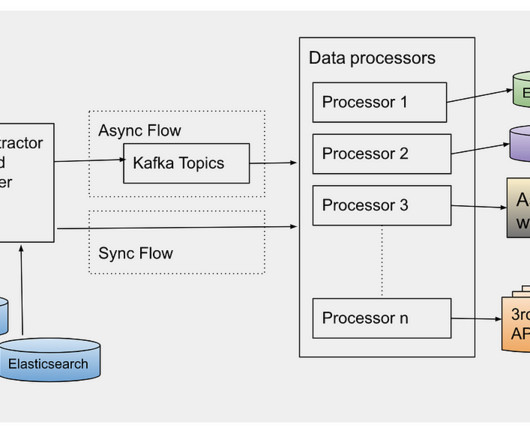
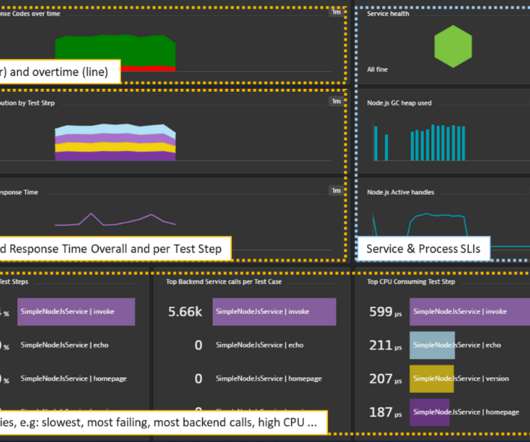
As a result, site reliability has emerged as a critical success metric for many organizations. By automating and accelerating the service-level objective (SLO) validation process and quickly reacting to regressions in service-level indicators (SLIs), SREs can speed up software delivery and innovation. Service-level objectives (SLOs).











































Let's personalize your content