

Driving your FinOps strategy with observability best practices
Dynatrace
MARCH 18, 2024
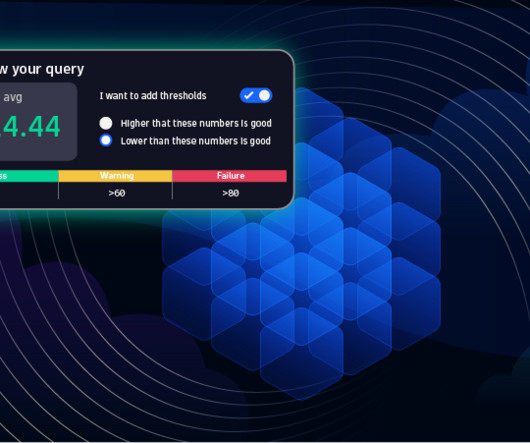
In a Dynatrace Perform 2024 session, Kristof Renders, director of innovation services, discussed how a stronger FinOps strategy coupled with observability can make a significant difference in helping teams to keep spiraling infrastructure costs under control and manage cloud spending.












































Let's personalize your content