
Best practices for Fluent Bit 3.0
Dynatrace
MAY 7, 2024
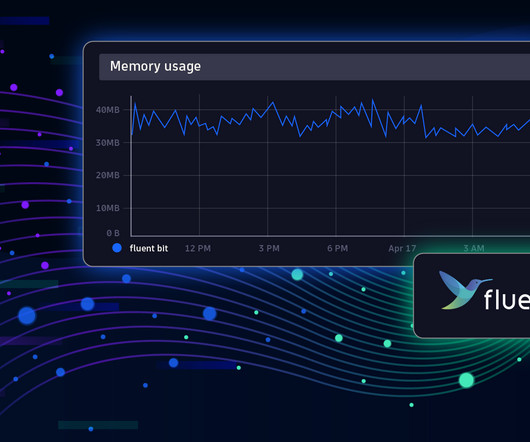
Fluent Bit is a telemetry agent designed to receive data (logs, traces, and metrics), process or modify it, and export it to a destination. Fluent Bit was designed to help you adjust your data and add the proper context, which can be helpful in the observability backend. Observability: Elevating Logs, Metrics, and Traces!










































Let's personalize your content