

Service level objective examples: 5 SLO examples for faster, more reliable apps
Dynatrace
JUNE 1, 2023
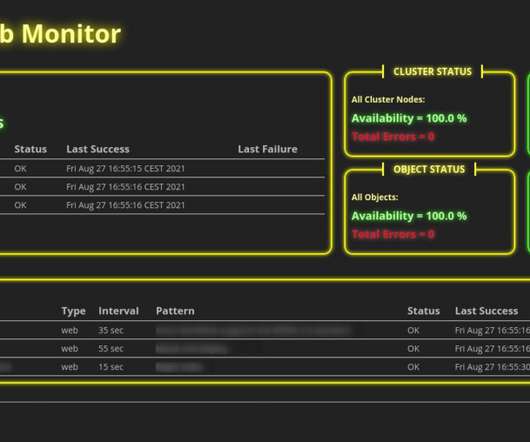
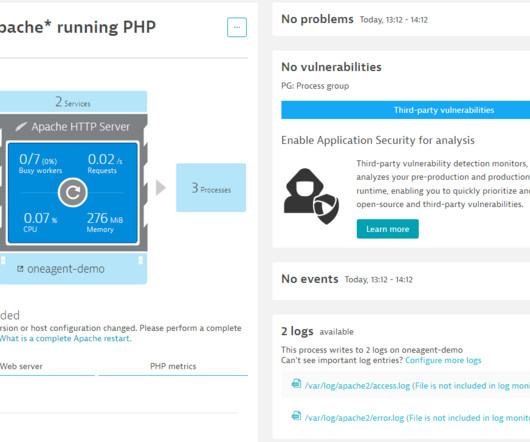
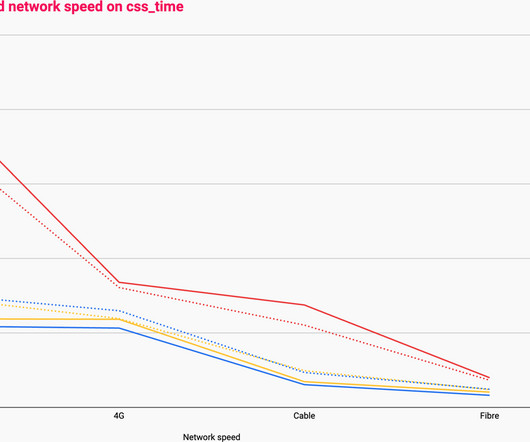
Certain service-level objective examples can help organizations get started on measuring and delivering metrics that matter. Teams can build on these SLO examples to improve application performance and reliability. In this post, I’ll lay out five SLO examples that every DevOps and SRE team should consider. or 99.99% of the time.










































Let's personalize your content