

Why applying chaos engineering to data-intensive applications matters
Dynatrace
MAY 23, 2024
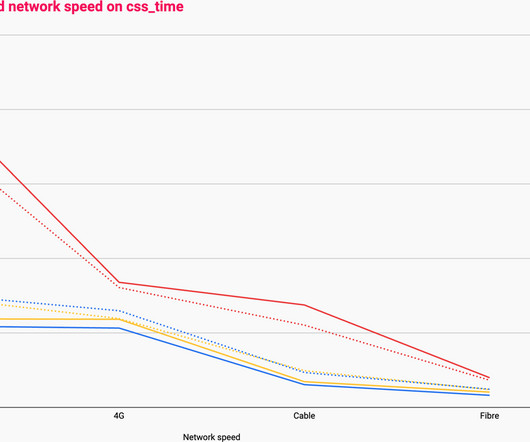
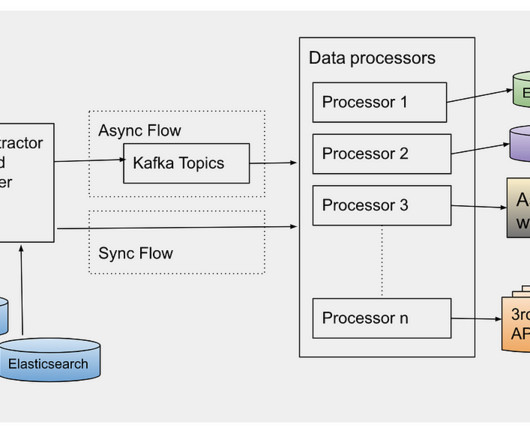
Stream processing One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data.




























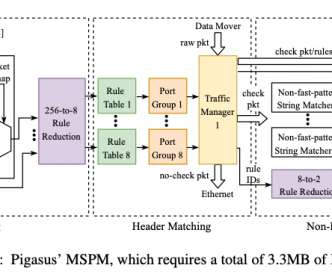

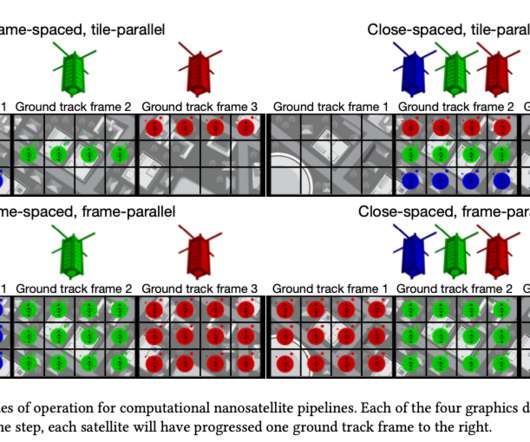

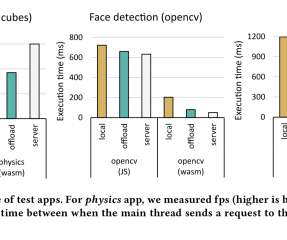

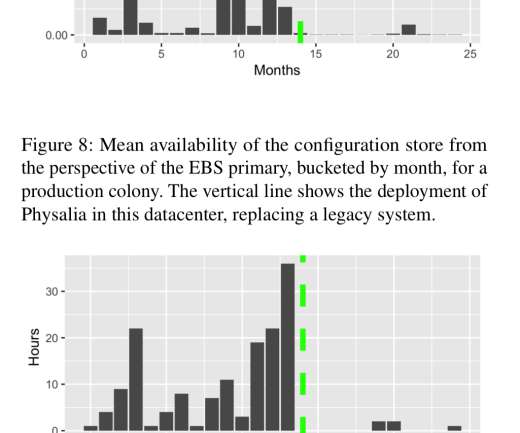










Let's personalize your content