
Optimize your environment: Unveiling Dynatrace Hyper-V extension for enhanced performance and efficient troubleshooting
Dynatrace
OCTOBER 23, 2023
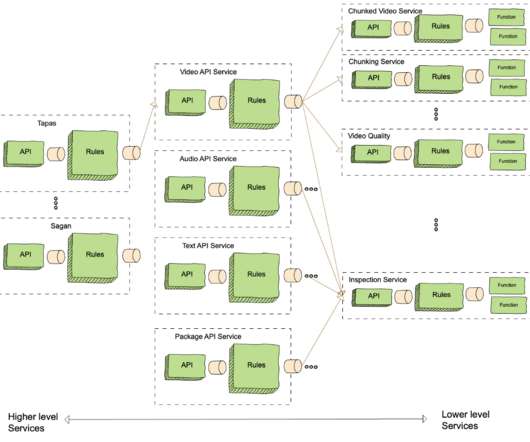
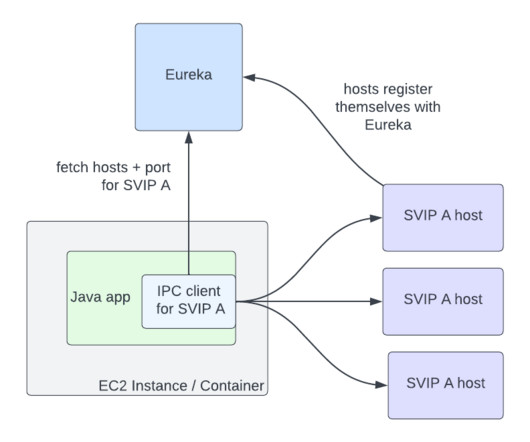
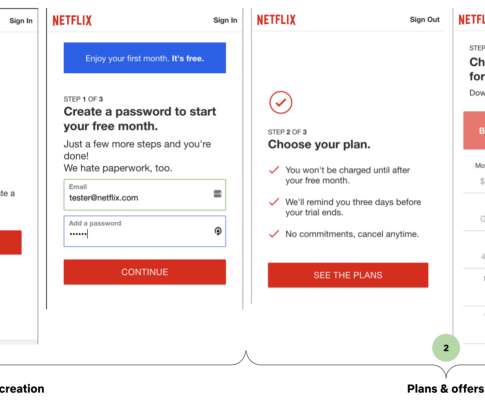
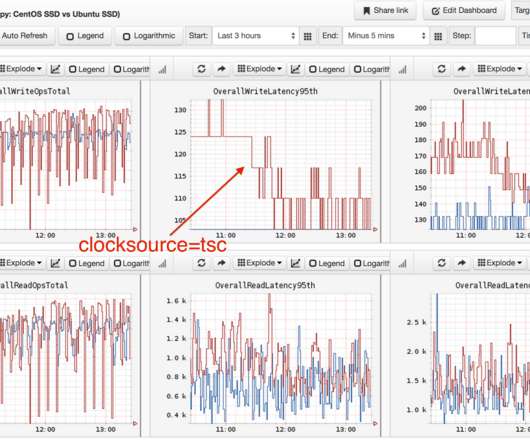
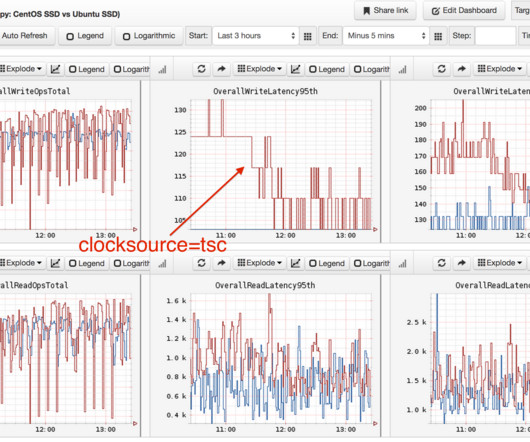
Therefore, they experience how the application code functions and how the application operations depend on the underlying hardware resources and the operating system managed by Hyper-V. This presents a challenge for IT operations teams, specifically in identifying and addressing performance issues or planning how to prevent future issues.





































Let's personalize your content