

In-Stream Big Data Processing
Highly Scalable
AUGUST 20, 2013
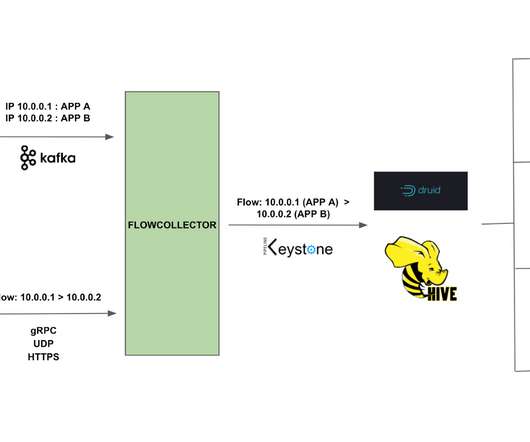
The shortcomings and drawbacks of batch-oriented data processing were widely recognized by the Big Data community quite a long time ago. As a result, the input data typically goes from the data source to the in-stream pipeline via a persistent buffer that allows clients to move their reading pointers back and forth.



















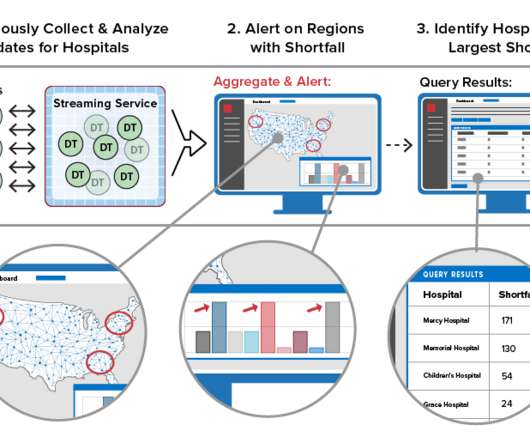
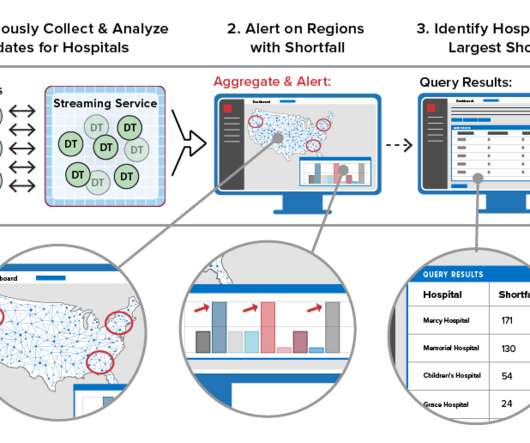














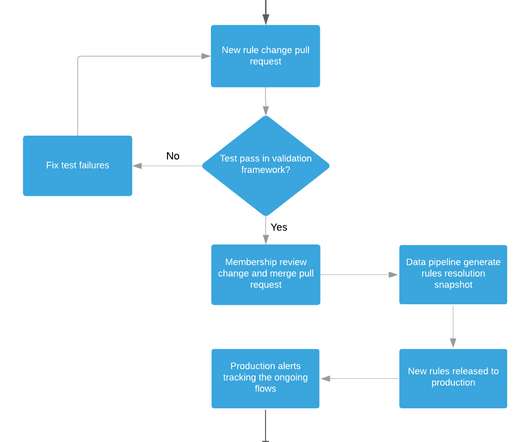






Let's personalize your content