Architectural Insights: Designing Efficient Multi-Layered Caching With Instagram Example
DZone
FEBRUARY 27, 2024
Leveraging this hierarchical structure can significantly reduce latency and improve overall performance.
 Architecture Efficiency Latency Systems
Architecture Efficiency Latency Systems 
DZone
FEBRUARY 27, 2024
Leveraging this hierarchical structure can significantly reduce latency and improve overall performance.
The Netflix TechBlog
SEPTEMBER 29, 2022
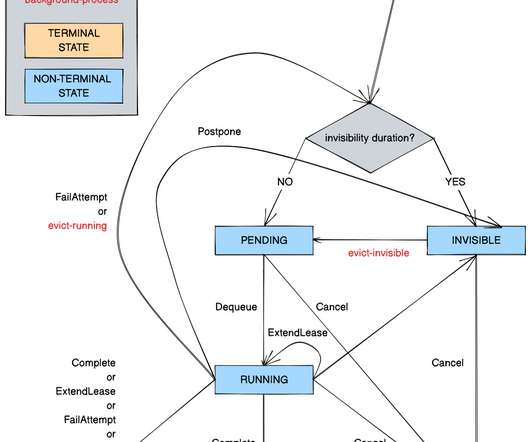
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Scalegrid
FEBRUARY 8, 2024
A distributed storage system is foundational in today’s data-driven landscape, ensuring data spread over multiple servers is reliable, accessible, and manageable. This guide delves into how these systems work, the challenges they solve, and their essential role in businesses and technology.

Dynatrace
JANUARY 26, 2021
Traditional computing models rely on virtual or physical machines, where each instance includes a complete operating system, CPU cycles, and memory. Within this paradigm, it is possible to run entire architectures without touching a traditional virtual server, either locally or in the cloud. What is serverless computing?

Scalegrid
MARCH 28, 2024
Key Takeaways Redis offers complex data structures and additional features for versatile data handling, while Memcached excels in simplicity with a fast, multi-threaded architecture for basic caching needs. Snapshots provide point-in-time captures of the dataset, which are efficient for recovery on startup.

Dynatrace
APRIL 8, 2024
This blog explores how vertically integrated risk management solutions that use AI and automation enable unparalleled visibility, control, and efficiency for risk management in banking. If system failures occur, teams must resolve them quickly and resolutely. Risk in banking is broad and interconnected. Automated issue resolution.

Dynatrace
JANUARY 31, 2024
GenAI is prone to erratic behavior due to unforeseen data scenarios or underlying system issues. Figure 1: Sample RAG architecture While this approach significantly improves the response quality of GenAI applications, it also introduces new challenges.

Expert insights. Personalized for you.





































Let's personalize your content