
Enhanced AI model observability with Dynatrace and Traceloop OpenLLMetry
Dynatrace
DECEMBER 4, 2023
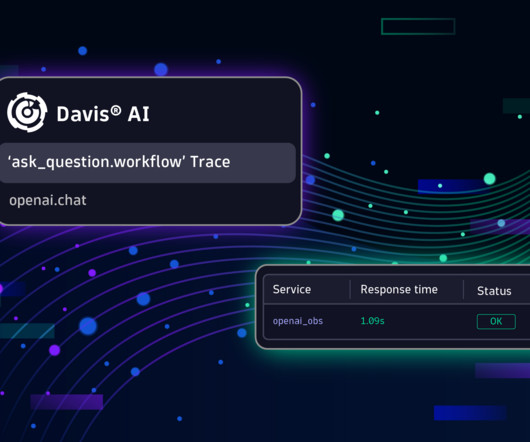
Data quality and drift: Monitoring the quality and characteristics of training and runtime data to detect significant changes that might impact model accuracy. Utilizing an additional OpenTelemetry SDK layer, this data seamlessly flows into the Dynatrace environment, offering advanced analytics and a holistic view of the AI deployment stack.






















Let's personalize your content