

Why applying chaos engineering to data-intensive applications matters
Dynatrace
MAY 23, 2024
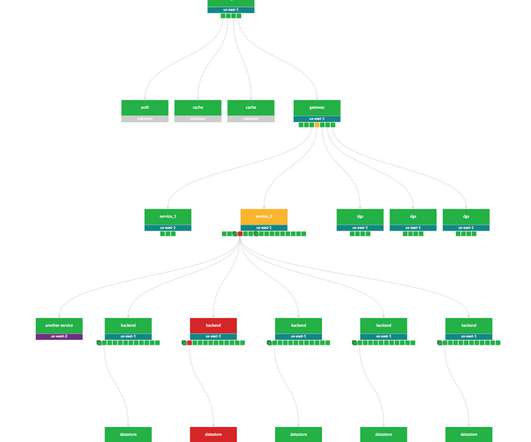
Stream processing enables software engineers to model their applications’ business logic as high-level representations in a directed acyclic graph without explicitly defining a physical execution plan. We designed experimental scenarios inspired by chaos engineering. This significantly increases event latency.












































Let's personalize your content