

Automatic and intelligent end-to-end observability for OpenTelemetry Java
Dynatrace
MAY 13, 2021
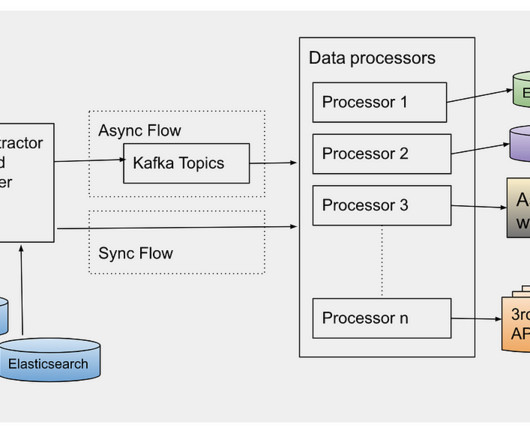
Oftentimes, this involves the integration of OpenTelemetry data that’s used during development into production workflows. Today, Dynatrace is happy to announce OneAgent support for discovering and automatically capturing OpenTelemetry trace data for Java. Dynatrace and OpenTelemetry work better together. Nano HTTPD ?(instead









































Let's personalize your content