

Dynatrace supports SnapStart for Lambda as an AWS launch partner
Dynatrace
NOVEMBER 28, 2022
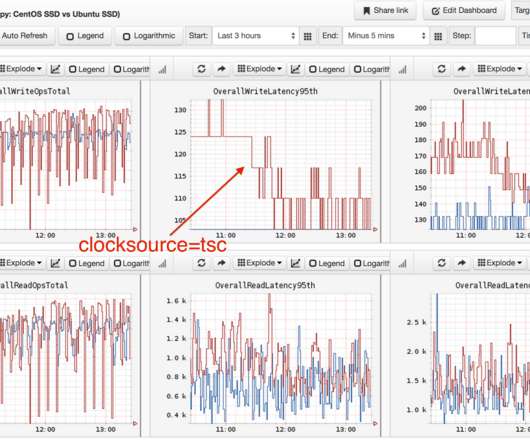
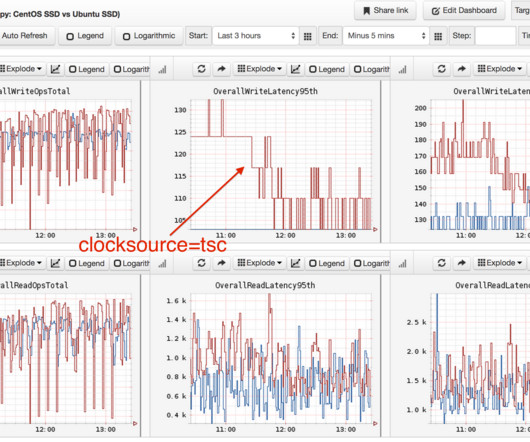
The new Amazon capability enables customers to improve the startup latency of their functions from several seconds to as low as sub-second (up to 10 times faster) at P99 (the 99th latency percentile). This can cause latency outliers and may lead to a poor end-user experience for latency-sensitive applications.


































Let's personalize your content